




I. Introduction▲
Le rendu différé tente de combiner les techniques de rendu conventionnelles (dans un espace 3D) avec les avantages des techniques s'appliquant en espace image (dans un espace 2D). Dans cet article, nous séparons l'éclairage du rendu : ainsi, l'éclairage devient une technique complètement applicable en espace image. Cette manière de faire possède quelques inconvénients, mais aussi d'importants avantages. Ces derniers incluent :
- le coût des lumières dépend principalement de la surface couverte à l'écran ;
- toutes les lumières sont calculées par pixel et toutes les surfaces sont éclairées de la même façon ;
- les lumières peuvent être bloquées comme tout autre objet, cela permet un rejet par la profondeur optimisé par le matériel ;
- les textures d'ombre sont peu coûteuses.
Les principaux désavantages sont :
- le tampon image est très grand ;
- un coût potentiellement élevé de remplissage de l'image ;
- il est difficile d'avoir des équations gérant plusieurs lumières ;
- la transparence est très difficile à effectuer.
I-A. Historique▲
Le concept d'éclairage différé semble apparaître dans un article de Takahashi et Saito, Comprehensible rendering of 3-D shapes(1), et dans le travail préparatoire effectué dans The Image Synthesizer(2) de Perlin, qui fournit ainsi une contribution importante à l'idée d'effectuer un post-traitement dans l'espace image pour l'évaluation des ombres. L'article de Takahashi et Saito est en fait une technique non photoréaliste (adaptée par Mitchell pour le temps réel(3)), mais ils mentionnent qu'elle pourrait être adaptée à du rendu photoréaliste (ce que présente cet article). La principale contribution introduite par Takahashi et Saito est les tampons géométriques (Geometry Buffers ou G-Buffers). Ceux-ci sont la pierre angulaire permettant à l'éclairage différé de fonctionner.
I-B. Rendu différé ou ombrage différé ou éclairage différé ?▲
Le terme « rendu différé » est utilisé pour décrire un certain nombre de techniques similaires ; elles partagent toutes l'étape de renvoi, mais diffèrent sur la partie du pipeline qui est retardée. Cet article ne retarde que la partie éclairage du pipeline, il n'impose aucune contrainte sur les autres parties, tant que le G-Buffer est rempli avant l'étape de l'éclairage. L'ombrage différé est typiquement utilisé lorsque le shader de la surface est différé, ce qui a été présenté dans le projet UNC Pixel Plane(4).
II. Concepts importants▲
II-A. Textures en tant que tableaux▲
Les textures peuvent être utilisées comme des tableaux à une, deux ou trois dimensions ; nous utilisons énormément cette fonctionnalité, il est donc nécessaire d'examiner les plus grosses différences entre les textures et les tableaux. Les textures ne sont pas des tableaux conventionnels et nous pouvons utiliser ces propriétés supplémentaires à notre avantage, mais il y a aussi des conséquences que nous pouvons en grande partie anticiper.
II-A-1. Dépassement mémoire▲
Les textures sont très efficaces pour gérer les accès en dehors des limites du tableau. Le mode d'accès aux textures contrôle la manière de gérer les dépassements, et cela, sur chaque axe séparément. Le mode le plus courant est d'utiliser une troncation, répétant ainsi le dernier texel à l'infini. Autrement, nous pouvons utiliser le mode permettant de faire une opération modulo sur les indices sans surcoût.
II-A-2. Interpolation linéaire▲
Le filtrage bilinéaire donne une interpolation linéaire sans surcoût entre les échantillons, ce qui est très pratique lorsque nous stockons des approximations discrètes dans une fonction. Le principal problème est que nous ne pouvons pas contrôler l'interpolation pour chaque axe indépendamment. Ce problème peut se résoudre en stockant une approximation discrète dans une fonction 1D suivant un axe de la texture et de stocker des fonctions différentes pour l'autre axe. Dans ce cas, nous souhaitons seulement avoir une interpolation linéaire et non bilinéaire. Deux approches existent pour obtenir une interpolation linéaire à partir d'une texture :
- La méthode manuelle, utilisant deux fois l'échantillonnage de la texture par point et faire l'interpolation linéaire dans le shader ;
- Une modification de la texture afin de répéter chaque échantillon, de telle sorte que l'interpolation linéaire « sans surcoût » sur l'axe que nous ne souhaitons pas retourne la même valeur que si nous avions fait un échantillonnage par point sur cet axe.
La seconde approche est coûteuse en espace de texture à cause de la copie supplémentaire de chaque échantillon, mais le pixel shader n'échantillonne la texture qu'une seule fois pour récupérer le résultat de l'interpolation linéaire, ce qui économise en échantillonnage de texture et en instructions arithmétiques. J'utilise généralement cette méthode.
II-A-3. Projection▲
Lors de l'échantillonnage d'une texture, nous pouvons en option spécifier une division de chaque coordonnée par la coordonnée W. Nous pouvons l'utiliser pour obtenir gratuitement une division à chaque fois que nous souhaitons obtenir quelque chose. Cela économise des instructions du pixel shader, notamment lors de la conversion d'une position dans la perspective d'un accès à une texture.
III. Tampons géométriques (G-Buffers)▲
Les tampons géométriques sont des images 2D et stockent les informations géométriques dans une texture, conservant les positions, les normales et toute autre information utile pour chaque pixel, notamment pour des opérations dans l'espace image en post-traitement. À l'origine, Takahashi et Saito les ont utilisées pour les contours, les hachures, etc. dans un rendu non-photoréaliste. Nous allons plutôt les utiliser comme paramètres dans nos équations des lumières afin d'évaluer un modèle de lumière photoréaliste après le rendu de toutes les géométries. Pour ce faire, nous devons aussi stocker l'information du matériau de la surface : en conséquence, notre tampon n'est pas strictement un G-Buffer, mais je m'y réfèrerai toujours comme tel.
L'ingrédient clé de l'accélération matérielle des G-Buffers est d'avoir la précision suffisante pour stocker et traiter les données telles que la position pour chaque pixel. Cela nécessite de traiter les pixels en virgule flottante (il est possible de faire autrement, mais c'est généralement très limité), mais plus haute est la précision que nous utilisons pour stocker l'information dans les G-Buffers, plus lent est le rendu. Habituellement, les nombres à virgule flottante semblent être une solution intéressante et surtout facile, mais souffrent d'un gros souci de performance : la grande taille (128 bits pour quatre canaux), la lenteur du rendu (jusqu'à quatre fois plus lent qu'avec des entiers sur 8 bits) ainsi que d'autres soucis (pas d'opérations après la transparence et une accélération matérielle limitée sous Direct3D) semble indiquer que nous devrions essayer d'implémenter les G-Buffers sans le support des flottants pour la cible du rendu.
L'élément nécessitant la plus grande précision est l'information de la position et celle-ci dépend de l'espace dans lequel nous la stockons. Idéalement, nous souhaitons avoir la position dans un espace où les erreurs de quantification affectent le moins possible l'éclairage.
III-A. Stocker la position▲
Comme nous stockons uniquement les positions qui apparaissent à l'écran, nous avons une plage finie à couvrir convenablement. Cette plage finie nous oriente vers un espace vue ou une transformation ultérieure. Nous souhaitons clôturer le champ de vision dans la boite englobante la plus petite (afin de réduire le gaspillage), mais faire passer une boite englobante dans un champ de vision en perspective n'est pas adéquat. Plus précisément, il y a énormément de gaspillage vers le plan proche. Cependant, si nous utilisons la boite englobante minimale après l'application de la perspective, il n'y a plus de gaspillage au niveau du plan proche. L'application de la perspective nous donne le même nombre d'unités que ce soit vers le plan proche ou le plan lointain et chaque unité couvre plus d'espace dans le monde vers le plan lointain(5).
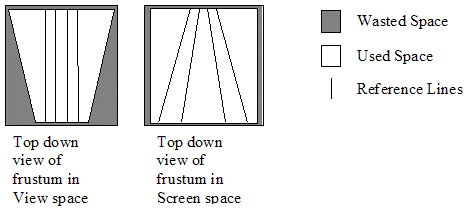
En stockant notre position dans l'espace écran (après l'application de la perspective, après la division homogène), nous pouvons stocker notre position comme un vecteur 3D qui est à la fois compact et de haute précision pour toute la vue. Cela coûte quelques instructions supplémentaires pour faire l'opération inverse, mais les avantages en bande passante et la fidélité visuelle rendent, d'après moi, cette opération utile.
L'utilisation de flottants sur 16 bits pour stocker la position dans l'espace vue est une autre solution. L'encodage en virgule flottante préservera la précision que ce soit pour le plan lointain ou proche, mais ne sera pas aussi précis que les entiers sur 16 bits utilisés pour la position dans l'espace écran. L'utilisation des flottants sur 16 bits pour stocker la position dans l'espace vue économisera des instructions : si la qualité est suffisante, c'est donc probablement mieux de l'utiliser(6). Le plus gros problème est que le rendu de quatre canaux au format flottant sur 16 bits n'est pas si courant et, pour couvrir l'ensemble du matériel DirectX 9, j'utilise des entiers sur 16 bits, car ils peuvent facilement accueillir deux entiers de 8 bits pour les cartes ne gérant que les cibles à quatre canaux d'entiers sur 8 bits (actuellement, cela impacte les NVIDIA GeForce FX).
Cela nous amène à deux fonctions HLSL : l'une prend la position HCLIP et la sauvegarde dans le G-Buffer, l'autre fait l'inverse, ce qui produit ainsi une position dans l'espace adéquat pour le shader (pour l'éclairage, j'utilise l'espace vue). La matrice qui nous emmène de la position écran du G-Buffer vers l'espace du shader prend automatiquement en compte l'opération de débiaisage. De plus, il garde le W en espace écran sans le modifier pour les effets de post-traitement, comme le brouillard ou la profondeur de champ. Les autres données dans les G-Buffer peuvent nécessiter leurs propres fonctions d'empaquetage, mais la plupart seront bien moins complexes que celles utilisées pour la position.
float3 PackPositionForGBuffer( float4 inp )
{
float3 o;
o.xyz = inp.xyz / inp.w;
o.xy = (o.xy * 0.5) + 0.5;
return o;
}
float4 UnPackPositionFromGBuffer( float3 inp )
{
float4 o;
o.xyzw = mul( float4(inp,1), matGBufferWarp );
o.xyz = o.xyz / o.w;
return o;
}Nous devons avoir assez de canaux pour stocker tous les paramètres de notre équation d'éclairage. Chaque implémentation aura ses propres besoins ; toutefois, il y a certains paramètres requis pour toutes :
- Position ;
- Normale ;
- Couleur ;
- Matériau.
Au minimum, cela nécessite dix canaux et, en pratique, nous allons en utiliser beaucoup plus. Actuellement, il n'y a pas de format de textures avec autant de canaux, ce qui signifie que nous devons utiliser plusieurs textures à la fois pour stocker toutes les données. J'ai tendance à utiliser seize canaux, ce qui permet d'avoir un peu d'espace supplémentaire pour personnaliser l'équation des lumières, mais douze devraient suffire pour la plupart des cas.
Le support matériel minimal pour les G-Buffer est donc les Pixel Shader 2 et le rendu vers une texture. Si le matériel ne gère que 8 bits par canaux, n'importe quel canal nécessitant plus de précision demandera une passe supplémentaire et doit être réassemblé lors de l'utilisation (actuellement, la NVIDIA GeForce FX a besoin de ces techniques, mais cela pourrait être corrigé au niveau du pilote dans le futur).
Si la carte autorise le rendu vers plusieurs textures (Multiple Render Targets [MRT], comme les ATI 9500 et supérieures), nous pouvons l'utiliser pour réduire le nombre de passes lors de la création du G-Buffer. Les cartes ATI 9500 et supérieures supportent jusqu'à quatre cibles de rendu simultanément et chaque cible de rendu peut être une surface A16B16G16R16, nous pouvons donc générer le G-Buffer de ce tutoriel en une seule passe. Les textures ayant de multiples éléments (Multiple Element Textures) peuvent aussi apporter une réduction similaire dans le nombre de passes, mais cette technique n'est pas très bien acceptée par le matériel pour le moment.
MRT et les cibles de rendu en entiers sur 16 bits permettent une passe unique pour utiliser le G-Buffer aussi simplement qu'un rendu standard. Pour les cartes sans MRT ou sans surfaces de précision suffisante, nous devons nous rattraper sur des techniques multipasses pour générer le G-Buffer.
IV. Aperçu de l'éclairage différé▲
Il y a trois étapes distinctes dans l'éclairage différé.
- L'étape géométrique.
- L'étape d'éclairage.
- Le post-traitement.
Chaque étape utilise des shaders DirectX (vertex et pixel shaders) mais l'objectif de chacun et les entrées sont différents. La sortie de chaque étape devient l'entrée de la prochaine avec la dernière étape (le post-traitement) affichant la géométrie et l'éclairage. En grande partie, le reste de cet article se concentre sur les deuxième et troisième étapes, lorsque les G-Buffers sont déjà remplis pour les techniques de rendu photoréaliste en espace écran.
Pour le moment, j'utilise le terme « shader » dans le sens de Renderman : le processus complet de rendu d'un objet(7). Souvent un « shader » consistera en un vertex shader et un pixel shader (et quelques fois avec plusieurs instances des deux).
IV-A. Étape géométrique▲
L'étape géométrique est la seule étape qui utilise les données des modèles. Son résultat est le G-Buffer ; elle prend en entrée toute donnée dont peuvent avoir besoin les objets. Au plus simple, cette étape est constituée uniquement d'opérations 2D (copie des données du G-Buffer) permettant l'éclairage sans avoir de rendu d'objet.
Chaque shader utilisé pour la géométrie est responsable du remplissage du G-Buffer avec les paramètres adéquats. Cette étape est approximativement équivalente au shader de surface de Renderman, la principale différence étant que ce dernier calcule les lumières, alors que notre système ne fait que produire les paramètres pour l'étape d'éclairage.
Habituellement, le tampon de profondeur est utilisé pour déterminer l'objet le plus proche pour chaque pixel. Si les shaders de cette étape sont très coûteux, il peut être avantageux de passer par une étape d'initialisation de la profondeur(8) (ici, toutes les géométries sont dessinées pour configurer le tampon de profondeur, puis la géométrie est redessinée avec les shaders finaux).
Le principal avantage par rapport à l'approche temps-réel conventionnelle des textures procédurales de Renderman est que le shader n'est utilisé que pour la génération des paramètres résultant et qu'il n'est exécuté qu'une seule fois, peu importe le nombre ou le type des lumières affectant la surface (la génération du tampon de profondeur peut nécessiter l'exécution du shader, mais normalement, avec des fonctions plus simples).
Un autre avantage est que, après cette étape, la méthode de remplissage du G-Buffer n'a plus d'importance, cela permet donc de mélanger des imposteurs et des particules avec les surfaces classiques et de les traiter de la même manière (lumière, brouillard, etc.).
Certaines parties constantes de l'équation de l'éclairage peuvent être calculées durant cette étape et stockées dans le G-Buffer si nécessaire. Cela peut être utilisé si vos lumières utilisent Fresnel (qui utilise généralement seulement la normale de la surface et la direction de la vue).
IV-B. Étape d'éclairage▲
La vraie puissance de l'éclairage différé est que les lumières sont mises en avant. Cette séparation complète entre l'éclairage et la géométrie permet aux lumières d'être recréées d'une manière totalement différente de celles d'un rendu standard. Cela rend le travail de l'artiste plus simple, car il y a moins de restrictions sur la façon dont les lumières affectent les surfaces. Cela permet un ajustement plus simple des lumières.
Les shaders de lumière ont un accès aux paramètres stockés dans le G-Buffer pour chaque pixel qu'ils illuminent. Ces paramètres seront personnalisés pour chaque moteur de rendu, mais, pour être vraiment utiles, la majorité inclut les mêmes paramètres vitaux pour l'éclairage photoréaliste. Cela comprend la position, la normale, les paramètres du modèle de lumière et les couleurs de la surface. Dans la plupart des cas, ces paramètres seront empaquetés, mais nous ignorons cela au cours de cette section et nous présumons que les paramètres sont prêts à être utilisés.
Je vais essayer d'emprunter les noms standards des variables de Renderman et des équations d'éclairage Phong/Blinn(9)(10). Certaines sont stockées dans le G-Buffer, d'autres sont des propriétés de la lumière et d'autres encore sont calculées dans le shader. De plus, toutes les variables ne seront pas utilisées pour tous les shaders.
IV-C. Variables d'éclairage▲
P = position de la surface dans l'espace vue
N = normale dans l'espace vue
E = position de l'œil dans l'espace vue (normalement <0,0,0>)
I = vecteur incident (de l'œil vers la position de la surface)
L = vecteur de la lumière
H = moitié de vecteur (N + L normalisé)
Cs0 = couleur 0 de la surface
Cs1 = couleur 1 de la surface
Cs = couleur de la surface (utilisée chaque fois que les couleurs de la surface ne sont pas indiquées)
Cl = couleur de la lumière
LB = tampon de lumière (la sortie des shaders des lumières)
Kd = coefficient de diffusion
Ks = coefficient spéculaire
Kamb = coefficient ambiant
Kemm = coefficient d'émission
IV-D. Modèle de lumière▲
Un des désavantages de l'éclairage différé est qu'il est tout aussi coûteux d'avoir plusieurs modèles de lumière. Bien que les modèles de lumière programmables soient considérés comme l'un des principaux avantages du pipeline programmable, l'amélioration de la qualité et du nombre de lumières peut compenser cet inconvénient. La méthode générique pour l'éclairage différé est de prendre un modèle qui peut gérer la majorité des types de surface que votre scène possède. Ici, vous devez faire un compromis entre le nombre de paramètres à stocker plus le coût de l'évaluation du modèle de lumière complet pour chaque pixel - contre le modèle de lumière suprême que vous voulez.
Le choix du modèle de lumière affectera le rendu plus que tout autre chose, il est donc utile de personnaliser les modèles existant plutôt que d'utiliser une simple implémentation sortie directement d'un article de recherche. J'ai choisi d'utiliser un sous-ensemble du modèle classique Phong/Blinn pour cet article. La raison est qu'il est facile de comprendre ce qui se passe sans rentrer dans la théorie des fonctions de distribution de la réflectivité bidirectionnelle (BDRF). Il est, de surcroît, facile à implémenter et à exécuter.
Le modèle Phong/Blinn découpe la lumière en quatre composants principaux : les lumières ambiante, émissive, diffuse et spéculaire. Les composantes ambiante et émissive sont calculées une seule fois, mais les composantes diffuse et spéculaire sont calculées pour chaque lumière.
Pseudo-code :
Pour chaque scène
LB = Kamb * AmbientColour + Kemm * Cs
Pour chaque lumière:
Diffuse = N dot L
Specular = (N dot H) ^ shininess
if( Diffuse > 0 )
LB += Cs * Diffuse * Cl * Kd;
if( Specular > 0 )
LB += Specular * Cl * Ks;Ce modèle simple possède un certain nombre de problèmes : le premier (et le plus connu) est que cela a tendance à tout rendre plastique. D'autres modèles de lumière bien meilleurs (comme Blinn/Cook/Torrance) peuvent être évalués directement, mais nous pouvons souvent produire des approximations de bonne qualité en modifiant le modèle de lumière traditionnel pour utiliser les capacités des cartes graphiques modernes.
Une chose que les cartes graphiques font très bien, c'est de lire les textures rapidement ; nous pouvons utiliser cette faculté pour remplacer de nombreuses portions statiques avec une table de correspondances. Les modèles de lumière plus avancés ont souvent différentes formes produites via les calculs N dot L et N dot H. Les modèles tels que ceux d'Oren/Nayer produisent une composante diffuse plus plate basée sur la composante de rugosité. Une rapide amélioration est de remplacer la diffuse constante et la fonction de spéculaire (la diffuse en a une, unitaire dans le modèle Phong/Blinn) avec une table de correspondances basée sur les paramètres du matériau.
Le résultat du produit scalaire varie entre -1 et 1, mais le modèle conventionnel n'utilise que la partie positive. Autant que possible, utilisez cette propriété pour sauvegarder de l'espace dans votre texture. Je préfère laisser le produit scalaire décider de ce qui se passe lorsque la normale de la surface est derrière la lumière. Cela nous permet de simuler les surfaces « enroulées », ce qui donne une bonne approximation dans le cas d'un petit nombre de types de surface transparente et de dispersion (en partant de l'hypothèse que le matériau transmet un peu de lumière de l'avant vers l'arrière). Dans le second canal de la texture contenant les produits scalaires, nous stockons un multiplicateur en cascade qui contrôle le prochain élément dans l'équation standard de la lumière. Cet élément est utilisé pour éliminer le reflet spéculaire lorsque la composante diffuse est derrière même si le résultat de N dot H indique qu'il est devant. Cela peut aussi être utilisé pour un éclairage personnalisé où les reflets spéculaires sont aussi affectés par le N dot L.
Maintenant, nous montrons le modèle Blinn/Phong standard en utilisant ce nouveau modèle amélioré.
// fonction de produit scalaire pour la diffuse
float2 Fa( float dotp )
{
// si la lumière est devant
if( dotp > 0 )
return float2(dotp,1); // résultat unitaire et multiplicateur en cascade = 1
else
return float2(0,0); // Tue la lumière et le multiplicateur en cascade = 0
}
// fonction de produit scalaire pour la spéculaire
float Fb( float dotp, float shininess )
{
// si la lumière est devant
if( dotp > 0 )
return pow(dotp, shininess); // résultat = shininess à la puissance
else
return 0; // Tue la lumière
}
Pour toutes les lumières
Diffuse = Fa(N dot L)
Specular = Fb(N dot H, shininess)
LB += Cs * Diffuse.x * Cl * Kd
LB += Specular * Cl * Diffuse.y * KsNous pouvons remplacer les fonctions Fa et Fb avec des textures si nous biaisons les produits scalaires pour avoir une variation entre 0 et 1. Pour permettre plus de flexibilité, nous pouvons utiliser des textures 2D, le second paramètre déterminant quelle fonction utiliser pour ce point sur la surface. Une autre propriété que nous souhaiterions est la possibilité pour le reflet spéculaire de prendre une couleur de lumière combinée avec la surface (plastique) ou juste la surface (métallique). Nous pouvons y arriver en ajoutant un autre paramètre qui contrôle l'interpolation linéaire entre les deux options.
Les composantes ambiante et émissive sont déterminées dans l'étape d'initialisation et la partie principale du modèle de lumière est contenue dans une fonction que la plupart des lumières appellent. Certaines lumières implémentent un terme propre permettant des conditions d'éclairage particulières, comme une lumière uniquement diffuse ou uniquement spéculaire. La fonction implémentant cette partie principale du modèle de lumière utilise Cs0 comme couleur de la surface pour la diffuse et Cs1 pour la spéculaire et l'émissive.
float3 Illuminate()
{
float2 Diffuse = tex2D( DotProductFuncs, float2(bias(N dot L), Fa) );
float2 Specular = tex2D( DotProductFuncs, float2(bias(N dot H), Fb) );
float3 output = Cs0 * Cl * Diffuse.x * Kd;
output += Specular.x * Lerp(Cs1*Cl, Cs1, Kspecblend) * Diffuse.y * Ks;
return output;
}Cela donne un modèle de lumière capable de reproduire (à un haut degré) Blinn/Phong, Oren/Nayer, l'enroulement et qui peut avoir un reflet plastique ou métallique. Cela permet aussi d'autres matériaux moins courants. Par exemple, en modulant Cs1 avec une fonction de Fresnel dans la phase géométrique, vous pouvez obtenir une composante spéculaire qui dépend de la vue ; Cs1 peut aussi être définie à travers une carte environnementale locale générée durant l'étape géométrique. Vous pouvez transférer Fb dans la portion diffuse en utilisant une fonction de Fb constante et en passant N dot L dans le multiplicateur en cascade. Aussi, en utilisant un Fb variable, vous pouvez accéder à un terme (N dot L)*Fb(N dot H). Même si le modèle de lumière est fixe, l'utilisation des fonctions de produit scalaire remplaçable nous donne une grande liberté dans la personnalisation des matériaux.
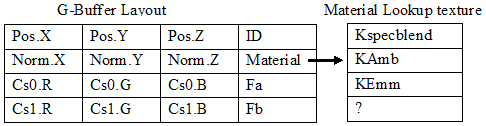
La fonction Illuminate est la principale contrainte sur le type de G-Buffer à utiliser. Nous devons stocker tous les paramètres nécessaires dans cette fonction. C'est au total 19 paramètres (position, normale, fonction de diffuse, fonction de spéculaire, Cs0, Cs1, Kd, Ks, Kspecblend, Kamb et Kemm) ce qui dépasse les 16 canaux de disponibles (vous pouvez ajouter plus de canaux au G-Buffer mais vous ne pouvez plus faire un rendu en une unique passe sur les cartes MRT). La réduction pour intégrer les paramètres dans le G-Buffer repose sur le fait que certains paramètres changent moins fréquemment et enlève certaines redondances. Quelques paramètres ne changent habituellement pas pour un même matériel, donc en gardant un index de matériel dans le G-Buffer nous pouvons les récupérer dans le shader de lumière. De plus Kd et Ks peuvent être prémultipliés dans Cs0 et Cs1 et n'ont pas à être explicitement stockés (La prémultiplication de Ks affecte la couleur émissive de mon modèle de lumière, mais je peux négliger cette erreur). De plus, j'ai ajouté un champ identifiant qui est expliqué plus tard.
IV-D-1. Lumières sur l'intégralité de l'écran▲
Pour les lumières qui sont réellement globales et qui n'ont ni position ni taille (les lumières ambiantes et directionnelles en font traditionnellement partie), nous créons un rectangle recouvrant l'intégralité de l'écran, ce qui provoque ainsi l'exécution du pixel shader pour chaque pixel. Le shader de lumière lit les paramètres à partir du G-Buffer, calcule la valeur de la lumière pour ce pixel et l'accumule dans le tampon de destination.
Nous devons initialiser le tampon de destination, nous exécutons donc le shader de lumière sur l'intégralité de l'écran. J'ai deux variantes courantes : une qui définit le tampon de destination à la valeur de la couleur ambiante globale et de la couleur des surfaces émissives, l'autre qui remplace la lumière ambiante par une simple source de lumière hémisphérique.
AmbientEmissiveLightShader( float3 AmbientColour )
{
LB = Kamb * AmbientColour + Kemm * Cs1;
}Une lumière hémisphérique utilise la surface de la normale et le vecteur haut du monde pour mélanger les deux couleurs (ici, les couleurs du ciel et du sol).
HemisphereEmmisiveLightShader( float3 GroundColour, float3 SkyColour, float3 WorldUp)
{
float dp = N dot WorldUp;
float blend = 0.5 + dp * 0.5;
float3 hemicol = Lerp(GroundColour, SkyColour,blend);
LB = Kamb * hemicol + Kemm * Cs1;
}L'autre lumière affectant tout l'écran est la classique lumière directionnelle. Ce type de lumière (connu sous le nom de « solaire » sous Renderman) présume que la lumière est infiniment lointaine et que les rayons de lumière sont parallèles pour l'intégralité de la scène. Cela signifie que le vecteur L est constant pour tout le shader de lumière. Pour l'observateur local, le vecteur incident I est différent pour chaque pixel, mais, avec un observateur infiniment lointain, il devient constant et produit un reflet spéculaire diminué. Je pars de l'hypothèse que nous avons un observateur local à travers mes exemples, mais il est trivial de le changer en un observateur infiniment lointain (I = <0,0,1> pour un observateur infiniment lointain, comme nous avons la lumière dans l'espace vue).
DirectionalLight( float3 LightDirection)
{
// pour un observateur local I = - la position de la surface normalisée
// point dans l'espace vue pour un observateur
// infiniment lointain I = <0,0,1> dans l'espace vue
I = normalize( -P );
L = LightDirection;
LB += Illuminate();
}IV-D-2. Lumières avec une forme▲
La seconde catégorie de lumières possède une position et une forme (comme les lumières ponctuelles, les spots, etc.). Celles-ci sont les plus intéressantes et sont habituellement plus rapides à l'exécution que les lumières couvrant l'intégralité de l'écran : dans un éclairage différé, le coût d'une lumière est proportionnel aux nombres de pixels couverts par la forme de la lumière, sachant qu'il y a une possibilité que ce nombre puisse être inférieur au nombre de pixels de l'écran. Cela amène à la situation inhabituelle où plusieurs lumières de tailles moyennes peuvent être plus rapides à calculer qu'une lumière directionnelle.
Les lumières ayant une forme peuvent être implémentées à l'aide d'un rectangle couvrant l'intégralité de l'écran, de la même façon que pour une lumière directionnelle, mais avec un algorithme différent pour calculer la direction des lumières et leur atténuation. Par contre, l'atténuation nous permet aussi de précalculer à quel moment la lumière n'apportera plus rien à la scène.
L'atténuation standard de DirectX/OpenGL(11)(12) utilise une équation quadratique que j'ai toujours trouvée difficile à manipuler et la partie constante fait que la lumière peut affecter toutes les surfaces indépendamment de leur distance par rapport à la lumière, nécessitant donc l'utilisation d'une lumière couvrant l'intégralité de l'écran. Le modèle d'atténuation que j'utilise est une simple texture de correspondances basée sur la distance. La distance est divisée par la distance maximale qu'une lumière peut affecter puis est utilisée pour accéder à une texture 1D. Le dernier texel devrait être 0 (pas de particule constante) si les optimisations suivantes sont utilisées.
float Attenuate( float3 LightPosition, float
MaximumLightRange )
{
float distance = | LightPosition - P |;
distance /= MaximumLightRange;
return tex1D( AttenuationTexture, distance );
}PointLight( float3 LightPosition, float
MaximumLightRange )
{
I = normalize( -P );
L = normalize( LightPosition - P);
float atten = Attenuate( LightPosition,
MaximumLightRange);
LB += Illuminate() * atten;
}Nous pouvons aussi implémenter facilement les spots en ajoutant un paramètre pour l'atténuation angulaire et utiliser le produit scalaire comme indice pour la texture. AngularFalloffCoord est utilisé comme seconde coordonnée pour sélectionner la diminution angulaire (chaque combinaison d'angle intérieur et extérieur aura une fonction 1D différente dans la texture 2D).
float AngularAttenuate( float3 LightDirection, float AngularFalloffCoord )
{
float dotp = -P dot LightDirection;
return tex2D( AngularAttenTexture. float2(bias(dotp)
, AngularFalloffCoord ) );
}SpotLight( float3 LightPosition, float
MaximumLightRange, float3 LightDirection,
float AngularFalloffCoord )
{
I = normalize( -P );
L = normalize( LightPosition - P);
float atten = Attenuate( LightPosition,
MaximumLightRange);
float anglularatten = AngularAttenuate(
LightDirection,
AngularFalloffCoord );
LB += Illuminate() * atten * angularatten;
}Grâce aux modèles d'atténuation, nous avons maintenant la distance maximale que la lumière peut atteindre ainsi que l'angle maximal. Nous pouvons maintenant calculer quels pixels sont hors de portée et essayer de ne pas exécuter le pixel shader sur ceux-ci. Malgré toutes les optimisations que nous pouvons faire au niveau des pixels à ignorer, le pixel shader de lumière reste à peu près le même.
La première approche est d'utiliser un rectangle aligné par rapport à l'écran, assez grand pour couvrir la lumière que nous devons calculer en projetant une sphère utilisant la position de la lumière et la distance maximale, à l'écran. Cela ne nécessite aucune modification par rapport à l'utilisation d'un rectangle couvrant l'écran, car tout ce que nous faisons est d'enlever à la louche les pixels où l'atténuation a réduit la contribution de la lumière à zéro.
V. Améliorer l'efficacité▲
Nous pouvons cependant faire beaucoup mieux que des rectangles de la taille des lumières pour la performance. Ceux-ci couvrent beaucoup de pixels où la contribution en lumière est nulle : même pour une lumière ponctuelle sphérique, les coins du rectangle sont perdus. C'est encore pire pour les spots. Dans le cas des spots, nous pouvons essayer avec une boîte englobante orientée, ce qui pourrait aider (mais pas beaucoup), sauf pour les lumières ponctuelles. Ce que nous souhaitons vraiment, c'est une projection 2D du volume où la contribution de la lumière n'est pas nulle.
Nous créons un modèle qui englobe le volume affecté par la lumière et tous les pixels qui ont été détectés présents dans son volume exécuteront le shader de lumière. Le matériel est très bon pour la projection, mais les besoins liés aux volumes de lumières sont différents des projections courantes. Il y a deux principaux besoins inhabituels nécessaires pour le shader de lumière :
- Chaque pixel doit être touché une et une seule fois. Si le volume de lumière provoque de multiples exécutions du shader de lumière, cela reviendrait à avoir plusieurs lumières affectant le pixel.
- Les plans de découpe proche et lointain ne doivent pas affecter la forme projetée. Nous ne voulons pas que la géométrie soit découpée par le plan proche et lointain : sinon, cela provoquerait des trous dans les lumières.
Le seul changement apporté au shader de lumière est dû à l'utilisation de géométries 3D plutôt que des rectangles. Nous devons donc utiliser des correspondances de texture de projection pour accéder au G-Buffer, puisque les coordonnées UV sont maintenant interpolées dans l'espace 3D.
Ces besoins sont proches de ceux liés aux techniques de volumes d'ombres, qui sont devenues récemment robustes et très compliquées. Nous pouvons dans plusieurs cas utiliser une solution plus simple (presque triviale), mais, dans les cas les plus extrêmes, nous devrons utiliser des techniques similaires aux volumes d'ombres.
V-A. Volumes de lumières convexes▲
La première et la chose la plus importante à noter est que, si la géométrie du shader de lumière est fermée et convexe, les solutions aux problèmes sont bien plus simples. Le premier problème est résolu grâce à un fait souvent oublié (en ces jours où les tampons de profondeur sont rapides) sur les objets convexes : la seule surface cachée à supprimer pour un objet convexe fermé est la face arrière (back face culling)(13). En d'autres mots, pour les volumes convexes, le premier problème est totalement supprimé simplement en utilisant la fonctionnalité de suppression des faces arrière ou avant.
Le second problème est grandement simplifié. J'ai été très prudent lorsque j'ai mentionné la suppression de la face avant ou arrière. En effet, les pixels seront couverts, et cela quelle que soit la face que vous supprimez, lorsque le tampon de profondeur est désactivé et qu'aucun découpage ne se produit. Les bons pixels seront aussi couverts si vous dessinez les faces arrière et utilisez le plan de découpe proche, mais pas le plan lointain et si vous dessinez les faces avant et utilisez le plan de découpe lointain, mais pas le plan proche. Malheureusement, il n'y a pas de solution simple si la géométrie est découpée par les deux plans : idéalement, nous aimerions garantir que cela n'arrivera jamais. Nous ne pouvons pas enlever le plan proche, mais nous pouvons effectivement retirer le plan lointain en le plaçant à l'infini.
Placer le plan de découpe lointain à l'infini n'a que très peu d'effets de bord (je laisserai la réflexion mathématique pour les gens meilleurs que moi(14)(15)), mais cela signifie que nous pouvons dessiner nos géométries convexes avec un plan lointain à l'infini et un découpage des faces avant et ainsi avoir les pixels appropriés touchés une fois - et seulement une, peu importe le découpage.
Les volumes convexes couvrent la majorité des shaders de lumières (par exemple, les sphères pour les lumières ponctuelles, les cônes pour les spots, etc.) et nous pouvons les adapter pour utiliser le rejet rapide basé sur la profondeur (fast z-reject), qui est normalement disponible.
V-B. Optimisations des occlusions du shader de lumière▲
Le matériel moderne possède généralement une sorte de tampon de profondeur hiérarchique, ce qui permet de rejeter les pixels très rapidement si le résultat du pixel shader n'est pas visible. En activant cette fonctionnalité pour notre shader de lumière, le temps d'exécution correspondra uniquement à l'éclairage qui est réellement vu, pixel par pixel. C'est-à-dire, si une lumière est grandement cachée par un mur, le shader sera exécuté uniquement pour les pixels qui ne sont pas couverts par ce mur.
La base de l'occlusion à partir des shaders de lumière est que le tampon de profondeur, étant utilisé pour la création du G-Buffer, est disponible sans coût (cela n'est vrai que si la résolution du G-Buffer est identique à celle du tampon de couleur de destination et que nous utilisons la même matrice de projection pour le shader des géométries et le shader des lumières). Si vous utilisez des rectangles de la taille des lumières, ce n'est qu'une question d'afficher un rectangle pour le point le plus proche du shader de lumière par rapport à la direction de la vue (ou le plan de découpe proche si le point le plus proche se trouve derrière) et d'activer le test de profondeur sans l'écriture de la profondeur. Si le test de profondeur échoue, alors quelque chose se trouve devant le point le plus proche de la lumière et donc la lumière en ce pixel ne pouvait être vue.
Le problème arrive lorsque nous essayons de combiner le test d'occlusion avec l'utilisation des géométries pour représenter le shader de lumière. Même avec des géométries convexes, il y a un conflit entre notre solution de découpe des faces avant et le besoin de la profondeur au point le plus proche. Pour utiliser la profondeur aux points les plus proches, nous devons dessiner les faces avant qui échoueront lors du test du plan de découpe proche (que nous ne pouvons pas supprimer). Finalement, nous devons produire une limite au plan le plus proche pour corriger le trou produit par la découpe, mais cela peut être une opération difficile et coûteuse pour le CPU.
Ma solution est bien plus simple ; je désactive simplement l'occlusion si le shader de lumière touche le plan proche et je dessine les faces arrières sans test de profondeur. Cela signifie que certains pixels seront exécutés par le pixel shader sans raison, mais c'est très peu coûteux pour le CPU et la différence ne touche que très peu de pixels.
V-C. Volume concave de lumière▲
Les lumières concaves sont utiles pour créer des lumières complexes. Leur problème est leur lien aux volumes d'ombrages, pour lesquels il sera probablement intéressant d'implémenter une technique d'ombrage robuste. Celles-ci ont été réfléchies longuement et sont maintenant très robustes et peuvent être modifiées pour utiliser des volumes concaves de lumières. La principale modification est qu'il faut ajouter le volume de telle manière que tout ce qui est à l'extérieur de celui-ci se retrouve dans l'ombre.
VI. Ombres▲
Il existe deux grandes techniques pour les ombres. Les volumes d'ombres qui sont identiques à ce qu'il y a dans un moteur classique, alors que les textures d'ombre (shadow maps) demandent quelques modifications.
VI-A. Textures d'ombre▲
Les textures d'ombre sont très faciles à intégrer dans un éclairage différé et possèdent de très bonnes performances. La clé est d'utiliser la variante peu utilisée connue sous le nom de forward shadow mapping(16). Avec les textures d'ombre standard, la texture est projetée sur l'objet et les profondeurs sont comparées. Avec le forward shadow mapping, la position des objets est projetée dans l'espace de la texture d'ombre, puis les profondeurs sont comparées dans cet espace.
La première étape est de calculer la texture d'ombre ; c'est exactement la même chose que dans un rendu conventionnel. Tous les objets affectés par la lumière sont dessinés dans une texture de profondeur (suivant le matériel que vous avez, cela peut être soit un tampon de profondeur, soit une texture haute précision) ; pour les lumières ponctuelles, six textures de profondeur sont dessinées (les faces d'un cube entourant la source de lumière).
Lorsque la lumière générant la texture d'ombre est affichée, la texture d'ombre est attachée au shader de lumière de façon standard (une texture de cube pour les lumières ponctuelles). Une matrice pour les ombrages est calculée afin de passer les points de l'espace vue à l'espace de l'ombre. Ensuite, le shader de lumière pour chaque pixel, transforme la position de la surface (dans l'espace vue) à travers la matrice en un point dans l'espace de l'ombre. Le point de l'espace de l'ombre fournit la profondeur de la surface ainsi que les coordonnées à projeter sur la texture d'ombre, ce qui donne la distance de l'ombre.
float PointSampleShadowMap( float4x4 ShadowWarpMatrix )
{
float4 PinShadow = mul( P, matShadowWarp );
float PDepth = PinShadow.z / PinShadow.w;
float SDepth = tex2Dproj( ShadowTexture, PinShadow );
if(PDepth < SDepth)
return 1; // not in shadow
else
return 0; // in shadow
}Pour un filtrage proportionnel au plus proche, nous ajoutons un peu d'imprécision sur les échantillons avant la récupération du texel et nous en faisons une moyenne. C'est une bonne chose de se rappeler que la comparaison s'effectue composante par composante, et que le produit scalaire d'un vecteur avec lui-même lorsque les valeurs de chaque composant sont 0 ou 1 est un accumulateur(17). Le coût d'un filtrage proportionnel pour quatre échantillons est bien moindre que le coût d'accès supplémentaire à la texture.
float PCF4SampleShadowMap( float4x4 ShadowWarpMatrix )
{
float4 PinShadow = mul( P, matShadowWarp );
float PDepth = PinShadow.z / PinShadow.w;
float4 SDepth;
SDepth.x = tex2Dproj( ShadowTexture, PinShadow +
Jitter0 );
SDepth.y = tex2Dproj( ShadowTexture, PinShadow +
Jitter1 );
SDepth.z = tex2Dproj( ShadowTexture, PinShadow +
Jitter2 );
SDepth.w = tex2Dproj( ShadowTexture, PinShadow +
Jitter3 );
float4 compare = (PDepth < SDepth.xyzw);
return (compare dot compare) *0.25;
}VII. Plus de contrôle sur la lumière▲
Un des grands avantages d'utiliser l'éclairage différé est que les surfaces et objets sont tous affectés de la même manière. Cependant, il arrive que ce soit aussi un problème. Dans de nombreuses cinématiques, les lumières sont paramétrées avec un intense effort pour s'assurer que les lumières et les ombres n'affectent pas des objets en particulier (comme l'éclairage qui n'illumine que les visages des stars du film ou s'assure que des ombres aléatoires ne vont pas cacher certains objets). C'est facile avec un système d'éclairage standard, mais l'éclairage différé rend cela plus compliqué. La solution est le paramètre d'identification stocké dans le G-Buffer.
Il permet à chaque objet de décider de la lumière qui l'affecte. Tous les objets ou surfaces ont un identifiant unique et cet identifiant est vérifié dans le shader de lumière. Le shader de lumière embarque une texture possédant un résultant booléen pour indiquer si l'identifiant de l'objet (utilisé comme coordonnées UV) doit être affecté.
Cela permet aussi d'avoir plusieurs équations de lumière en ayant plusieurs fonctions d'illumination et d'utiliser l'identifiant pour sélectionner laquelle utiliser. Actuellement, c'est très coûteux, mais, lorsque nous aurons des embranchements dynamiques dans le pixel shader, cela pourrait devenir rapide.
Une autre approche pour avoir des équations de lumière différentes est d'utiliser un système d'éclairage différé hybride où certains objets évitent (complètement ou partiellement) le système d'éclairage différé et illuminent directement le tampon de lumière. Évidemment, on perd la majorité des avantages, mais cela peut être pratique si vous avez quelques objets qui ne correspondent pas à votre modèle d'éclairage différé.
VII-A. Image à haute plage dynamique (HDR)DEBEVEC, P. Rendering synthetic objects into real scenes: Bridging traditional and image-based graphics with global illumination and high dynamic range photography. In SIGGRAPH 98 (July 1998)▲
L'éclairage différé aurait semblé facile à étendre pour utiliser les images à haute plage dynamique (HDR), avec des surfaces ayant des couleurs à canaux de 16 bits, un tampon destination d'éclairage qui peut être de n'importe quelle précision et une étape de post-traitement pour effectuer une correction des tons. Il semblerait donc que les images à haute plage dynamique soient la base pour ce type de rendu. Malheureusement, le matériel actuel ne peut pas faire un fondu alpha dans les textures qui ont plus de 8 bits de précision, ce qui signifie qu'il n'y a pas de méthode facile pour accumuler la contribution des lumières.
Une solution est de conserver un second tampon temporaire (de la même taille et résolution que le tampon d'éclairage) qui aurait été la sortie des shaders de lumière et ceux-ci auraient eu le « vrai » tampon d'éclairage comme entrée et auraient effectué l'accumulation des lumières à la fin du shader. Enfin, la géométrie des lumières serait traitée à nouveau, mais avec un simple pixel shader qui copie le tampon temporaire et remplace tous les pixels totalement identiques dans le « vrai » tampon. Cela n'ajoute qu'un petit coût par shader de lumière pour gérer les images à haute plage dynamique (le coût supplémentaire du vertex shader et l'exécution du pixel shader basique) comme l'opération de copie ne copie uniquement les pixels qui ont été modifiés. Par contre, les changements d'état peuvent être prohibitifs en temps d'exécution.
VIII. Shaders de post-traitement▲
Cette dernière étape est optionnelle et peut être divisée en deux si elle est trop complexe. Ici nous souhaitons prendre la scène complètement éclairée et ajouter n'importe quel autre effet, par exemple du brouillard, une profondeur de champ ou une correction des tons. De plus, les particules non éclairées et les surfaces transparentes seraient ajoutées au cours de cette étape.
Les entrées sont tous les tampons générés précédemment (G-Buffer et tampon d'éclairage) et la sortie sera le tampon arrière pour l'affichage. Dans son état le plus simple, cette étape n'existe pas et le tampon d'éclairage correspond au tampon arrière (le suréchantillonnage peut survenir durant les shaders de lumières en apportant quelques modifications à ceux-ci). Dans le cas le plus complexe, l'étape écrit des surfaces temporaires avant que le traitement final envoie le résultat dans le tampon arrière.
Les étapes intermédiaires sont nécessaires si le suréchantillonnage pour l'anticrénelage est utilisé. Actuellement, l'anticrénelage rapide est réalisé à travers du multiéchantillonnage avec un tampon de profondeur/stencil haute résolution, mais un tampon de couleurs à la résolution standard. Le tampon de profondeur/stencil haute résolution est utilisé pour calculer le filtrage du tampon de couleurs. Il ne peut pas être utilisé avec un G-Buffer, car vous ne pouvez pas filtrer correctement ses valeurs (pour être parfaitement exact, vous pouvez filtrer le G-Buffer, mais cela nécessite un filtre complètement programmable).
La principale technique d'anticrénelage pour les G-Buffers est de tout générer à une plus haute résolution et de filtrer lors du post-traitement (une autre technique serait de faire en sorte que les shaders de lumière utilisent des filtres personnalisés lorsqu'ils lisent les données venant du G-Buffer). Malheureusement, lorsque cela est réalisé, il n'y a pas de méthode (actuellement) pour filtrer le tampon de profondeur/stencil, le post-traitement doit donc être réalisé sans le tampon de profondeur. Cela affecte toutes les étapes intermédiaires. La première étape du post-traitement a accès au tampon de profondeur et subira le suréchantillonnage alors que la seconde étape affiche les pixels à la résolution de la sortie.
VIII-A. Brouillard▲
Le brouillard peut être basé simplement sur la distance ou reposer sur des effets volumétriques complexes (bien que, pour avoir un vrai brouillard volumétrique, il devra être intégré aux shaders de lumière). Le brouillard basé seulement sur la distance accède à la position à partir du G-Buffer et, suivant celle-ci, atténue la couleur dans le tampon d'éclairage. Selon la forme exacte de brouillard et les surfaces, il peut être possible de faire le fondu dans la phase de calcul des transparences.
float4 DistanceFog(float4 fogColour, float2 uv )
{
float projDist = Gbuffer.Pos[uv].z
/ Gbuffer.Pos[uv].w;
float t = tex1D( projDist );
return lerp( LB, fogColour, t);
}VIII-B. Profondeur de champ▲
L'effet de profondeur de champ actuellement disponible que je préfère est la technique en temps réel développée par Guennidi Riguer(18) et qui peut être facilement adaptée à notre système d'ombrage différé. L'idée de base est de calculer la distance à partir du plan focal et de l'utiliser pour contrôler la taille d'un « cercle de confusion ». Ce cercle est utilisé pour l'accès à l'image : plus grand est le cercle, plus l'image finale est floue.
L'algorithme s'adapte facilement à notre système d'éclairage différé, mais dépasse la limite d'instructions en dessous de PS_2_0 (la version de Riguer calcule quelques valeurs - comme le facteur de flou - dans la passe géométrique, alors que nous utilisons des paramètres « génériques », nous la calculons donc à la volée). Vous pouvez soit réduire le nombre de coups utilisés dans le « cercle de confusion », soit le découper en plusieurs passes ou encore passer à une version des shaders moins limitative.
float ComputeBlur( float depth, float focalDist, float
focalRange )
{
return saturate(abs(depth - focalDist) * focalRange);
}
float4 RiguerDOF( float focalDist,
float focalRange,
float maxCoC,
float2 tapOffset[NUM_OF_TAPS]
float2 uv )
{
float depth = Gbuffer.Pos[ uv ].z;
float blur = ComputeBlur( depth, focalDist,
focalRange);
float4 colourSum = Lit[ uv ];
float sizeCoC = blur * maxCoC;
float totalContrib = 1.0f;
for(i=0;i < NUM_OF_TAPS;i++)
{
float tapUV = uv + tapOffset[ i ] * maxCoC;
float4 tapColour = Lit[ tapUV ];
float tapDepth = Gbuffer.Pos[ tapUV ].z;
float tapContrib = (tapDepth > depth) ? 1.0f :
ComputeBlur(tapDepth, focalDist, focalRange);
colourSum += tapContrib;
totalContrib += tapContrib;
}
return colourSum / totalContribution;
}IX. Considérations pratiques▲
La première chose que vous remarquez lorsque vous avez ce système en place est que cela est très limité par le pixel shader. Les pixel shaders gourmands sont exécutés plusieurs fois pour chaque pixel. C'est l'une des raisons faisant que les géométries de lumières fonctionnent si bien : même si vous dessinez un grand nombre de triangles pour obtenir la bonne forme, les gains dans l'occlusion et la diminution des pixels gâchés dépassent le coût du vertex shader dans sa transformation des géométries.
Les textures d'ombre correspondent parfaitement à cette architecture, où le coût de la génération de la texture d'ombre génère effectivement la texture d'ombre. Le coût d'utilisation d'une texture d'ombre ne prend que quelques cycles par pixel. Même le filtrage proportionnel au plus proche n'est que très peu coûteux. Comme les textures d'ombres ne doivent pas être mises à jour chaque image, il est facile d'avoir beaucoup d'ombres. Le coût d'utilisation d'une lumière avec une ombre par rapport à une lumière sans ombre peut être réduit à six instructions de pixel shader par pixel.
L'éclairage différé change totalement le comportement que vous attendez des algorithmes d'éclairage complexe : un grand nombre de petites lumières est plus rapide que les grandes lumières couvrant beaucoup d'espace écran. Si votre monde est densément obstrué, la plupart de vos lumières ne vont rien coûter du tout. Cela provoque un effet étrange sur les performances, où l'éclairage d'un plan plat est bien plus gourmand que l'éclairage d'un environnement complexe.
X. Problèmes▲
X-A. Transparence▲
La transparence est un défaut majeur. Il n'y a pas de solution peu gourmande pour les cas « standard » de transparence. Le mieux que nous pouvons faire (en termes de vitesse) est de retourner à un système de rendu non différé pour les surfaces transparentes et les fusionner lors du post-traitement. La meilleure (en termes de rendu) est d'utiliser la fonctionnalité matérielle de depth-peeling. Chaque couche séparée exécute un ensemble complet de shaders de lumières avec l'aide du tampon stencil pour limiter la couverture des pixels puis fusionne le résultat(19).
X-B. Mémoire▲
Aucune solution, mais un avertissement sur le fait que l'éclairage différé possède de nombreuses grandes cibles de rendu. Si le suréchantillonnage est utilisé, les cibles de rendu sont plus grandes encore. Avec 16 bits par composante pour le G-Buffer, les 16 composantes prennent jusqu'à 256 bits par pixel, puis 32 bits pour le tampon de profondeur/stencil pour un total de 288 bits par pixel. Pour une résolution de 1024x768, le G-Buffer seul prend 28 Mo de mémoire vidéo (et il reste le suréchantillonnage). De plus, il y a le tampon d'éclairage et d'autres encore pour le post-traitement.
XI. Conclusions▲
L'éclairage différé est maintenant possible grâce au matériel des dernières cartes vidéo. Il possède ses propres avantages et désavantages et, alors que les désavantages dépassent les avantages sur le matériel actuel, dans les bonnes situations, il peut surpasser et être plus beau que l'éclairage par pixel conventionnel. Dans des situations avec des shaders procéduraux complexes et de nombreuses lumières et ombres, le gain peut être imposant et c'est encore plus vrai dans les environnements densément obstrués. Les mêmes techniques utilisées pour accélérer les objets (comme le batching) peuvent être utilisées pour accélérer les lumières et si une lumière n'est pas visible, cela ne consomme que très peu de ressources.
Sur le long terme, l'occlusion et les propriétés géométriques de l'éclairage différé sont les facteurs les plus intéressants. Aucune autre technique ne vous permet de dessiner autant de lumières agissant sur une même surface sans paralyser les performances(20). L'éclairage différé est bien plus extensible.
 |
 |
 |
 |
XII. Remerciements▲
Cet article est une traduction autorisée de l'article publié par Dean Calver sur Beyond3D.
Je tiens à remercier dourouc05 pour sa relecture lors de la traduction de cet article, ainsi que f-leb pour sa relecture orthographique.