

 La première préversion publique de CUDA 7.5 est disponible pour tous les développeurs CUDA enregistrés auprès de NVIDIA. La principale nouveauté est la gestion des nombres à virgule flottante codés sur seize bits, cest-à-dire la moitié de lencodage traditionnel (float sur trente-deux bits). Cette format est principalement utilisée pour du stockage de données quand la précision requise nest pas très importante, mais aussi pour des calculs sous la même hypothèse.
La première préversion publique de CUDA 7.5 est disponible pour tous les développeurs CUDA enregistrés auprès de NVIDIA. La principale nouveauté est la gestion des nombres à virgule flottante codés sur seize bits, cest-à-dire la moitié de lencodage traditionnel (float sur trente-deux bits). Cette format est principalement utilisée pour du stockage de données quand la précision requise nest pas très importante, mais aussi pour des calculs sous la même hypothèse.Calculs sur seize bits
Leffet sur la performance du code peut être énorme : la bande passante requise est divisée par deux, ce qui permet de transmettre deux fois plus de nombres par unité de temps sur les bus existants, den stocker deux fois plus sur la même quantité de mémoire. Ils pourront donc se révéler très utiles pour les applications où ces éléments sont limitatifs, comme lapprentissage de réseaux neuronaux de grande taille ou le filtrage de signaux en temps réel.
Lavantage en temps de calcul nest disponible que sur les GPU ayant une partie prévue pour larithmétique sur seize bits, ce qui nest pas le cas pour la majorité des processeurs disponibles, sauf sur Tegra. La prochaine architecture de GPU de NVIDIA, connue sous le nom de Pascal, aura des transistors alloués pour les calculs sur seize bits : le nombre de calculs effectués par seconde doublera entre les précisions FP16 et FP32 (le même rapport quentre FP32 et FP64). Entre temps, les calculs seront effectués en interne sur les mêmes circuits que précédemment, avec une précision bien plus élevée que des circuits dédiés (bien quelle soit en grande partie perdue lors de larrondi vers les seize bits).
Réseaux neuronaux
Lun des chevaux de bataille actuels de NVIDIA est lapprentissage automatique, en particulier par réseaux neuronaux, plus spécifiquement profonds, par exemple pour une utilisation dans les voitures intelligentes. Ils ont par exemple développé la bibliothèque cuDNN (CUDA deep neural network), qui accélère les calculs par un GPU. La troisième version de cette bibliothèque a été optimisée, particulièrement au niveau des convolutions (FFT et 2D), ce qui améliore la performance lors de lentraînement de réseaux neuronaux (gain dun facteur deux pour lapprentissage sur des GPU Maxwell). Elle gère également les nombres en virgule flottante sur seize bits, ce qui est utile pour des réseaux très grands, mais naméliore pas (encore) les temps de calcul.

CUDA vient également avec la bibliothèque cuSPARSE pour lalgèbre linéaire sur des matrices creuses accélérée sur GPU. Une nouvelle opération vient dy être ajoutée, nommée GEMVI, utilisée pour la multiplication entre une matrice pleine et un vecteur creux la sortie étant évidemment un vecteur plein. Ce genre dopérations est très utile pour lapprentissage automatique, plus particulièrement dans le cas du traitement des langues. En effet, dans ce cas, un document rédigé dans une langue quelconque (français, anglais, allemand ) peut être représenté comme un comptage des occurrences de mots dun dictionnaire ; bien évidemment, tous les mots du dictionnaire (même partiel) ne sont pas présents dans le texte, sa représentation vectorielle contient donc un grand nombre de zéros, il est donc creux. Une fois le dictionnaire défini, pour améliorer lefficacité des traitements, le dictionnaire peut être réduit en taille pour nen garder quun sous-espace vectoriel qui préserve la sémantique des textes : la transformation de la représentation du texte demande justement un produit entre le vecteur creux initial et une matrice de transformation.
C++11 et fonctions anonymes
La version précédente de CUDA a commencé à comprendre C++11, la dernière itération du langage de programmation. Les fonctions anonymes (lambdas) en font partie et servent notamment à écrire du code plus concis. CUDA 7.0 ne les tolérait que dans le code exécuté côté client, pas encore sur le GPU : ce point est corrigé, mais seulement comme fonctionnalité expérimentale. Par exemple, un code comptant les fréquences de quatre lettres dans une chaîne de caractères pourra sécrire comme ceci :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 | void xyzw_frequency_thrust_device(int *count, char *text, int n) { using namespace thrust; *count = count_if(device, text, text+n, [] __device__ (char c) { for (const auto x : { 'x','y','z','w' }) if (c == x) return true; return false; }); } |
La même fonctionnalité permet décrire des boucles for pour une exécution en parallèle, avec une syntaxe similaire à OpenMP, par exemple une somme de deux vecteurs (SAXPY pour BLAS) :
| Code c++ : | Sélectionner tout |
1 2 3 4 5 6 7 | void saxpy(float *x, float *y, float a, int N) { using namespace thrust; auto r = counting_iterator(0); for_each(device, r, r+N, [=] __device__ (int i) { y[i] = a * x[i] + y[i]; }); } |
Profilage
La dernière nouveauté annoncée concerne le profilage de code, nécessaire pour déterminer les endroits où les efforts damélioration de la performance doivent être investis en priorité. CUDA 7.5 améliore les outils NVIDIA Visual Profiler et NSight Eclipse Edition en proposant un profilage au niveau de linstruction PTX (uniquement sur les GPU Maxwell GM200 et plus récents), pour détermines les lignes précises dans le code qui causent un ralentissement. Précédemment, le profilage ne pouvait se faire quau niveau dun noyau, équivalent dune fonction pour la programmation sur GPU (temps pris par le noyau à lexécution, importance relative par rapport à lexécution complète).
CUDA 6 avait déjà amélioré la situation en affichant une corrélation entre les lignes de code et le nombre dinstructions correspondantes. Cependant, un grand nombre dinstructions nindique pas forcément que le noyau correspondant prendra beaucoup de temps à lexécution. Pour remonter jusquà la source du problème, ces informations sont certes utiles, mais pas suffisantes, à moins davoir une grande expérience. Grâce à CUDA 7.5, le profilage se fait de manière beaucoup plus traditionnelle, avec un échantillonnage de lexécution du programme, pour trouver les lignes qui prennent le plus de temps.
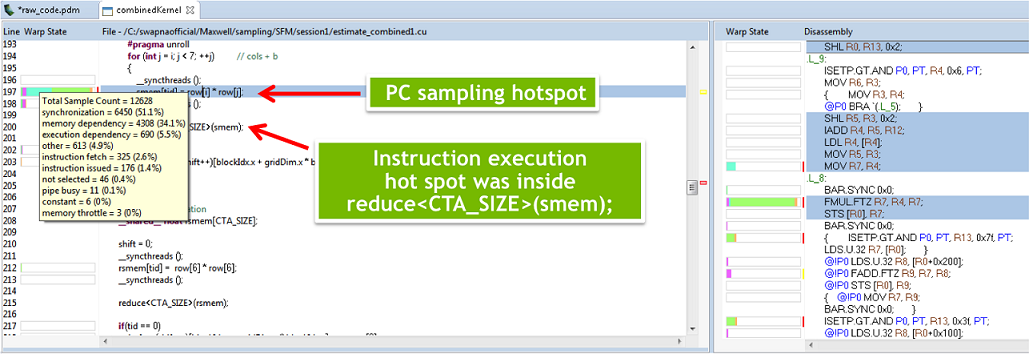
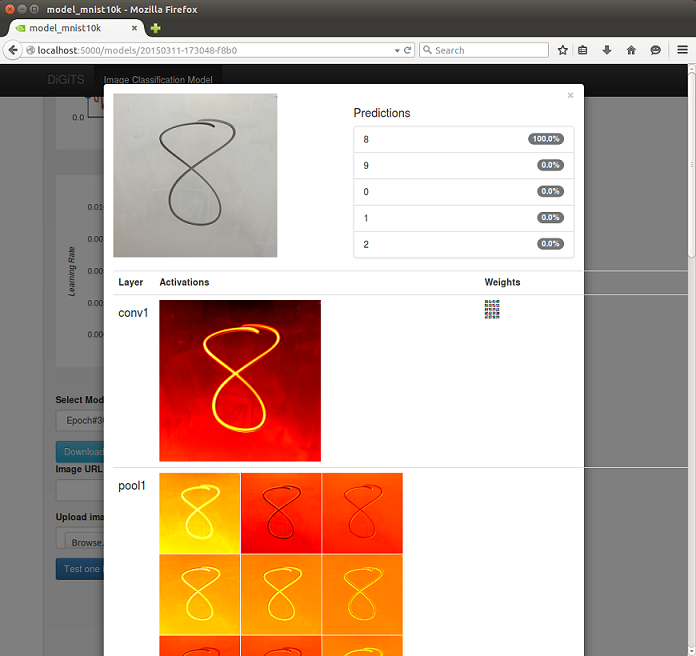
Sources et crédit des images et du code source : New Features in CUDA 7.5, NVIDIA @ ICML 2015: CUDA 7.5, cuDNN 3, & DIGITS 2 Announced.
Vous avez lu gratuitement 6 017 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.


