




Traduction▲
Cet article est une traduction de l'article en espagnol de Pablo Zurita "Arquitectura Multihilos Para Motores 3D" (http://www.pablo-zurita.com.ar/spanish/2007/07/26/arquitectura-multihilos-para-motores-3d/http://www.pablo-zurita.com.ar/spanish/2007/07/26/arquitectura-multihilos-para-motores-3d/), traduit par Michaël Gallego (https://bakura.developpez.comhttp://bakura.developpez.com).
Un débat sur ce sujet est en cours sur le forum : Que peut apporter le multithread au développement de jeux ?Que peut apporter le multithread au développement de jeux ?.
Abstract▲
Les processeurs de plusieurs cœurs sont maintenant très répandus et ne sont plus l'apanage exclusif des serveurs et des super-calculateurs. La plupart des ordinateurs personnels et consoles de jeux vidéo utilisent maintenant des processeurs multi-cœurs qui permettent d'exécuter de manière parallèle plusieurs flots de données. D'autre part, la vitesse de chaque cœur s'est stabilisée et il est difficile d'améliorer la performance d'une application qui s'exécute sur un seul cœur simplement en multipliant le nombre de ces cœurs. Créer une architecture pour des applications 3D qui utilisent un tel hardware est un nouveau défi car il nécessite l'interaction entre plusieurs sous-systèmes. Dans cet article, on expliquera l'architecture du Chromaticity Engine (NB : le moteur 3D de l'auteur original de cet article - Pablo Zurita -), un moteur 3D qui fut pensé pour les applications interactives. L'objectif final de cet article est de montrer les différents inconvénients de créer un moteur 3D optimisé pour les applications interactives, et comment nous avons résolu ces problèmes dans le Chromaticity Engine.
Introduction▲
La complexité des moteurs 3D et des applications les utilisant rend très difficile le portage d'un simple cœur à plusieurs cœurs. Au niveau de l'architecture, les différents sous-systèmes d'un moteur sont souvent dépendants entre eux, et il y a donc deux manières de voir les choses. La première est d'utiliser la même architecture que celle utilisée pour un cœur, mais de créer plusieurs threads pour certaines fonctions. L'avantage de cette méthode est que la majorité du code n'est pas modifiée, et que des APIs comme OpenMP permettent de simplifier grandement ce processus. Le problème de cette solution réside dans le fait que deux modèles fondamentalement différents sont mélangés : le modèle utilisé pour les processeurs simple cœur, et le modèle utilisé pour les processeurs multi-cœurs. Il est donc quasiment impossible de tirer parti au maximum de ces nouveaux processeurs. L'autre modèle consiste à laisser chaque sous-système se mettre à jour de manière indépendante, tout en maintenant une certaine cohérence entre ces sous-systèmes. Ce modèle permet d'utiliser de manière plus efficace les ressources de ces nouveaux processeurs multi-cœurs grâce à une architecture adéquate. C'est ce modèle qui est utilisé dans le Chromaticity Engine et qui sera expliqué.
Il faut noter que les architectures multi-cœurs varient grandement d'une plate-forme à l'autre, et qu'il est donc nécessaire que cette architecture soit suffisamment flexible pour s'adapter à ces différentes plates-formes. Nous allons observer trois types de processeurs principaux :
- Le Cell Broadband Engine de Sony, Toshiba et IBM, utilisé notamment dans la console PlayStation 3.
- Le Xenon d'IBM, utilisé dans la console Xbox 360 de Microsoft.
- Le Core 2 d'Intel, utilisé dans les PC ainsi que dans la dernière série de Macs d'Apple.
Compte tenu de ces différences, nous allons décrire plus en détail l'architecture de ces processeurs.
Processeurs ▲
Les différences entre les processeurs que nous allons évaluer sont majeures. La première différence se note dans la quantité de cœurs de chaque processeur et la capacité de calcul de chacun de ces cœurs.
Dans le cas du Core 2 d'Intel, nous avons un processeur de deux ou quatre cœurs, un cache L1 de 64 KB pour chaque cœur, un cache L2 de 4 MB partagé, est out of order (http://en.wikipedia.org/wiki/Out-of-order_execution) et un thread hardware pour chaque cœur [1, 2, 3]. Ce processeur est très facile à programmer puisqu'il partage de nombreuses caractéristiques avec les processeurs des générations précédentes. Le plus important est que le cache L2 est très grand. Une première idée consisterait à assigner un cœur à un ou plusieurs sous-systèmes du moteur jusqu'à utiliser tous les cœurs disponibles.
Le Xenon d'IBM est un processeur à trois cœurs, avec un cache L1 de 64KB pour chaque cœur, un cache L2 de 1 MB partagé entre les trois cœurs et le GPU, une exécution in order (http://en.wikipedia.org/wiki/Out-of-order_execution), et deux threads symétriques en hardware pour chaque cœur [4, 5]. Il est important ici de noter que bien qu'il paraît très différent du Core 2, nous allons voir que les différences sont bien moindres par rapport au Cell. Dans tous les cas, certaines différences vont devoir être prises en compte dans l'architecture du moteur. Tout d'abord, l'exécution dans l'ordre des instructions va entraîner une perte de performance si nous n'organisons pas bien les instructions à exécuter, notamment si un thread effectue une instruction complexe. De plus, le cache L2 est bien plus petit que celui d'un Core 2, mais il reste suffisamment grand pour ne pas trop modifier notre architecture générale. Nous pouvons donc faire les mêmes remarques que pour le Core 2 : une première idée consisterait à assigner chaque cœur à un ou plusieurs sous-systèmes même si, dans ce cas, il faut faire davantage attention à la façon de gérer les informations et l'ordre d'exécution.
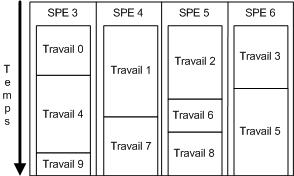
Enfin, le Cell Broadband Engine de Sony, Toshiba et IBM est un processeur avec un "Power Processor Element" (PPE), chargé de contrôler six ou huit "Synergistic Processing Elements" (SPE). Le PPE a un cache L1 de 64KB, un cache L2 de 512KB et deux threads gérés en hardware. Ce cœur a comme fonction principale de contrôler les SPEs et de réaliser des opérations qui ne se subdivisent pas bien dans les SPE. Chaque SPE a 256KB de mémoire sans cache, il a un modèle d'exécution in order (http://en.wikipedia.org/wiki/Out-of-order_execution) et un seul thread en hardware [6, 7, 8]. C'est le processeur le plus compliqué à programmer. Les SPE ont un cache très petit ce qui implique une séparation de chaque travaux afin de maintenir chaque SPE occupé. Il est donc impossible d'assigner un SPE à un sous-système car la combinaison d'un cache très petit et d'une exécution dans l'ordre créeraient des goulots d'étranglement. Un soin tout particulier devra donc être apporté au planificateur de tâches du moteur afin que chaque SPE soit occupé, tout en ne bloquant pas sur une tâche en particulier [9].
Parallélisme ▲
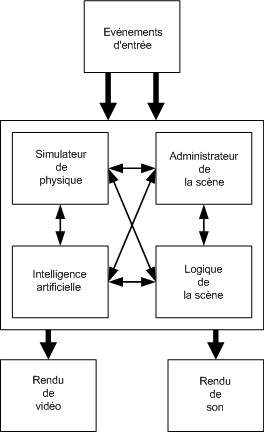
Maintenant que nous en savons un peu plus sur l'architecture de ces processeurs multi-cœurs, nous allons définir un modèle de parallélisme afin que chaque plate-forme soit supportée, en évitant de créer une architecture trop compliquée à maintenir. On ignorera donc la possibilité de paralléliser chaque fonction puisque le gain de performance est relativement minime [10]. D'autre part, nous devons prendre en compte l'interaction entre chaque sous-système d'un moteur 3D (Figure 1). Il faut donc trouver une solution qui permette l'interaction entre chacun de ces sous-systèmes, sans que cela implique une complexité excessive qui ferait perdre tout intérêt à une parallélisation du code.
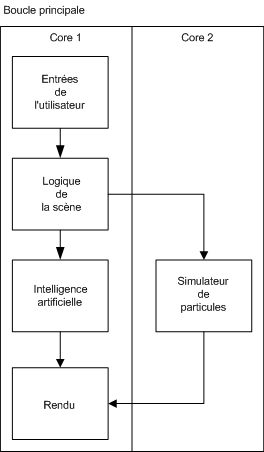
Un modèle de parallélisation consisterait à maintenir une boucle principale similaire à celle utilisée dans une architecture simple cœur, et de, tout simplement, paralléliser les sous-systèmes qui n'interagissent pas avec les autres [11]. Par exemple, si nous avons un sous-système "simulateur de particules", nous pouvons le rendre parallèle au système d'intelligence artificielle et d'exécuter de manière simultanée dans différents cœurs ces deux tâches (Figure 2). Hélas, ce modèle est peu utile dans le cadre d'un moteur 3D car la quantité de sous-systèmes pouvant être parallélisés sont limités. Pour ce modèle, des processeurs comme le Cell attendraient patiemment des instructions pour être exécutées sur les différents SPEs mais, de manière générale, 80% des SPEs resteraient libres. Ce modèle permet donc peu de liberté sur la manière d'utiliser les différents cœurs.
Le Chromaticity Engine utilise un modèle hybride de parallélisation puisque chaque sous-système se met à jour de manière totalement parallèle afin de travailler constamment avec la dernière information disponible pour chacun des autres sous-systèmes. De plus, chaque sous-système dispose d'un niveau de parallélisation supplémentaire pour les objets indépendants entre eux dans ce sous-système.
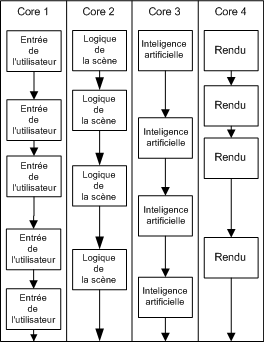
Le premier niveau de parallélisation consiste à placer dans chaque cœur un sous-système spécifique (Figure 3). La dépendance entre chacun de ces sous-systèmes continue d'exister, mais dès qu'un sous-système à terminé une tâche, tous les autres sous-systèmes sont mis à jour avec la dernière information de ce premier sous-système. Le grand avantage de cette méthode est qu'il est très scalable sur le nombre de processeur, et que chaque système peut être exécuté sur son propre cœur.
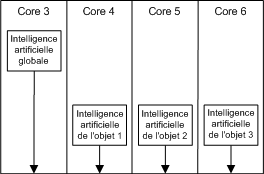
Le deuxième niveau de parallélisation se déroule au niveau de chaque sous-système. Dans un sous-système, certaines opérations sont indépendantes et il est donc possible de réaliser ces opérations en parallèle (Figure 4). Par exemple, si nous avons un sous-système "animation" qui va modifier la géométrie des objets dynamiques de la scène, il est possible d'animer deux objets de manière parallèle puisqu'un objet ne dépend pas de l'autre. Ce modèle de parallélisation n'est pas utile dans une architecture comme le Core 2 d'Intel puisque la quantité de cœurs est plus ou moins égale au nombre de sous-systèmes d'un moteur, dans la majorité des cas. Toutefois, dans le cas d'un processeur comme le Cell, ce modèle est très important puisque les SPEs, très nombreux, peuvent contenir peu d'information.
Une caractéristique que chaque plateforme partage est le fait qu'il soit nécessaire de créer des "points de synchronisations" lorsque l'exécution d'un ou plusieurs sous-systèmes est plus rapide ou plus lente que les autres sous-systèmes. Par exemple, si la mise à jour des sons audio est trop lente par rapport au reste, il y aura au final un décalage entre les sons et l'image. Il est donc nécessaire de créer certains points de synchronisations afin que tous les systèmes restent synchronisés.
Scheduler ou planificateur de tâches ▲
Une grosse erreur de design consisterait à laisser chaque sous-système décider lui même quel cœur utiliser. La raison est que, soit le sous-système ne dispose pas d'information suffisante pour prendre une bonne décision sur quel cœur utiliser, ou alors la logique sur quel thread utiliser dans chaque sous-système, pouvant créer de gros soucis de maintenance et de performance. Pour cette raison, le Chromaticity Engine dispose d'un planificateur de tâches se chargeant de gérer toutes les opérations à exécuter. Ce scheduler va être différent pour chaque type de processeur. Dans le cas du Core 2, on peut obtenir de bonnes performances en laissant un ou plusieurs sous-systèmes dans chaque thread, tandis que dans le cas du Cell, le travail sera différent et plus complexe puisqu'il devra assigner différents SPEs à chaque processus de chaque sous-système. Il faut aussi noter que le scheduler ne peut pas construire et détruire des threads constamment car cela entraînerait une baisse importante de performance. De plus, un thread ne doit jamais être tué mais commettre un "suicide" car tuer un thread est une des opérations les plus coûteuses sur toutes les plates-formes [12, 13].
Pour le Core 2 d'Intel, le scheduler devra garder les sous-systèmes équilibrés sur les différents threads. Pour ceci, il est nécessaire de récupérer des données sur les différents sous-systèmes afin de modifier les sous-systèmes présents sur chaque thread. Un des problèmes est qu'il n'y a pas de moyen de spécifier de manière définitive sur quel cœur va s'exécuter un thread. Sous Windows, on peut suggérer un cœur à utiliser via la fonction SetThreadAffinityMask, mais elle ne nous assure pas qu'un thread s'exécutera effectivement sur le cœur désiré. Il est donc plus judicieux de laisser le scheduler de Windows décider à notre place sur quel cœur tel thread prendra place.
La politique de planification du Xenon est relativement similaire à celle du Core 2. Toutefois, il est nécessaire de spécifier quel thread utiliser, sinon tous les threads que nous créons vont être exécutés sur le même thread que le thread que nous venons de créer. Pour ceci on doit utiliser la fonction XsetThreadProcessor avec l'argument 0 ou 1 pour le coeur 1, 2 ou 3 pour le coeur 2, et 4 ou 5 pour le coeur 3. A part ça, le scheduler effectuera les mêmes opérations que celui du Core 2.
Enfin, le scheduler du Cell est quant à lui très différent et bien plus complexe. Chaque travail envoyé à chaque SPE devra être plus petits. Le scheduler va donc résider dans le PPE et va s'assurer que le moteur utilise tous les SPEs. Pour ceci, le scheduler devra récupérer en temps réel le temps d'exécution du thread de chaque SPE. Le modèle que nous allons décrire est plus ou moins similaire à [14], où le scheduler possède une file FIFO (First In First Out) de différentes tâches qui seront exécutées sur les SPEs. Il est très important que chaque tâche soit la plus petite possible. En effet, comme nous l'avons vu plus haut, le cache de chaque SPE est très petit et, de plus, les instructions s'exécutant de manière ordonnées, une tâche trop grosse provoquera rapidement un goulot d'étranglement et donc une baisse de performance. Il faut donc garder des tâches les plus petites possibles de manière à ce que le SPE soit de nouveau libre le plus rapidement possible.
Portabilité et maintenance ▲
Maintenir un moteur 3D pour plusieurs plates-formes est une tâche complexe. D'autant plus complexe si l'on souhaite en plus la portabilité. Les différentes APIs disponibles pour chaque architecture de processeurs sont différentes entre elles. Si nous souhaitons quelque chose de facilement maintenable, il est donc nécessaire de séparer au maximum du reste du moteur le code spécifique à chaque plate-forme. Par exemple, utiliser un système de #define pour créer un nouveau thread ne serait pas une bonne idée. Il est nécessaire d'abstraire toutes les opérations spécifiques de telle manière que le scheduler puisse créer un thread de manière transparente sans qu'il sache comment créer ce thread sur la plate-forme utilisée. Quand tout le code est ainsi "caché" de manière modulable, il est bien plus facile de maintenir une seule version du moteur, de le porter à d'autres plates-formes et même pour faire des tests. Il est donc nécessaire de prendre en compte les différentes APIs pour chaque plate-forme. Par exemple, la création de threads se base sur Boost Threads [15]. A la fin, nous n'obtenons donc pas une classe qui supporte tout ce qu'une bibliothèque contiendrait, mais plutôt différentes opérations minimales afin d'obtenir les résultats souhaités sur toutes les plates-formes. Le reste du moteur utilisera donc ces fonctions plutôt que des fonctions spécifiques à une plate-forme.
Résultats ▲
Le Chromaticity Engine a été testé sous plusieurs plates-formes. Pour tester ses performances, nous avons créé une scène avec 524 288 objets dynamiques, chacun de 18 triangles. A aucun moment nous n'avons ni dessiné la scène ni lancé des sons afin d'éviter de fausser les résultats à cause du GPU. Le moteur devait, ici, maintenir un graphe de scène avec toute la géométrie de la scène et, en plus, réaliser un octree (subdivision de l'espace de la scène).
Pour la version PC, le moteur fut testé sous Windows Vista avec un Core 2 Duo E6700, Core 2 Quad QX6600 et un AMD Athlon X2 6000+. Le gagnant fut évidemment le Core 2 Quad QX6600 grâce à l'utilisation de ses 4 cœurs (Figure 6). Comme spécifié précédemment, il n'est pas possible de spécifier de manière certaine sur quel cœur sera exécuté tel ou tel thread.
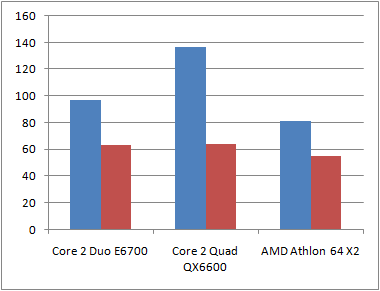
Les gains de performances du moteur comparés au moteur tournant sur un seul coeur avec un seul thread sont donc notables.
Pour la version du Cell, le moteur a été exécuté sur une PlayStation 3 sur Yellow Dog Linux 5.0. Ici, la différence entre utiliser un cœur sur le PPE et le SPE, contre utiliser deux cœurs sur le PPE et les SPEs est très notable (Figure 7).
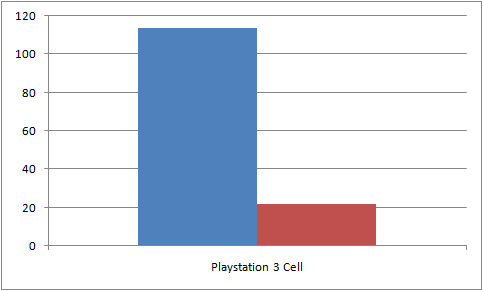
Nous n'avons pu effectuer de mesures pour le Xenon car il nous fallait le SDK de Microsoft, seulement disponible pour les studios de jeux vidéo et les créateurs de middleware.
Conclusion ▲
Le Chromaticity Engine est un moteur 3D qui a été écrit en réponse aux changements récents des processeurs. Nous sommes passés d'un seul thread en hardware à, au minimum, un thread en hardware par cœur (au minimum, 2). De plus, les différents cœurs n'augmentent plus de fréquence aussi rapidement qu'auparavant, ce qui implique que nous n'auront dorénavant moins de gains de performances si nous n'utilisons plus qu'un seul cœur [11]. De ce fait, il est aujourd'hui nécessaire de créer une architecture multithreads qui soit facile à maintenir et à porter sur différentes plates-formes. Grâce aux modèles de parallélisation, il est possible de créer des moteurs 3D compatibles avec les architectures de différents processeurs, et donc d'éviter l'écriture d'un code trop compliqué et difficile à maintenir.
Il sera nécessaire, dans le futur, de valider au mieux l'architecture décrite dans cet article, bien que nous avons déjà pu l'essayer sur une quantité limitée de plates-formes avec succès. Il serait notamment intéressant d'analyser les performances de cette architecture dans le domaine des visualisations scientifiques dans lesquelles les architectures des processeurs sont très différentes.
Références▲
- [1] O. Wechsler. Inside Intel® Core™ Microarchitecture: Setting new standards for energy-efficient performance, 2006.
- [2] J. Doweck. Inside Intel® Core™ Microarchitecture and Smart Memory Access: An in-depth look at Intel innovations for accelerating execution of memory-related instructions, 2006.
- [3] R.M. Ramanathan. Intel® Multi-Core Processors: Making the move to Quad-Core and beyond, 2006.
- [4] J. Brown. Application-customized CPU Design: The Microsoft Xbox 360 CPU story, 2005.
- [5] J. Andrews, N. Baker. Xbox 360 System Architecture. IEEE Micro Volume 26, Issue 2, 2006.
- [6] M. Gschwind, H. P. Hofstee, B. Flachs, M. Hopkins, Y. Watanabe, T. Yamazaki. Synergistic Processing in Cell's Multicore Architecture. IEEE Micro Volume 26, Issue 2.
- [7] J.A. Kahle. Introduction to the Cell Multiprocessor, 2005.
- [8] D. Pham. The Design and Implementation of a First Generation Cell Processor, 2005.
- [9] D.A. Brokenshire. Maximizing the Power of the Cell Broadband Engine Processor: 25 tips to optimal application performance, 2006.
- [10] H. Sutter. A Fundamental Turn Toward Concurrency in Software. Dr. Dobb's Journal, 2005.
- [11] A. El Rhalibi, D. England, S. Costa. Game Engineering for a Multiprocessor Architecture, 2005.
- [12] B. Dawson. Coding For Multiple Cores on Xbox 360 and Microsoft Windows, 2006.
- [13] Cell Broadband Engine Programming Handbook, 2006.
- [14] D. Mallinson, M. DeLoura. CELL: A New Platform for Digital Entertainment, 2005.
- [15] W.E. Kempf. The Boost C++ Libraries: Boost Threads, 2003.