





I. Un peu d'histoire▲
Si vous vous intéressez uniquement aux nouvelles fonctionnalités, allez faire un tour directement au paragraphe Direct3D 11. Ce qui suit est intéressant d'un point de vue historique mais n'est pas indispensable pour la compréhension de Direct3D 11.
DirectX 11, c'est le fruit d'une longue histoire. C'est l'histoire du graphisme sur PC. Il n'y a pas si longtemps que ça, on classait les puces graphiques en fonction du nombre de couleurs et de pixels, voire de caractères de texte, que l'on pouvait afficher. La partie qui nous intéresse, à savoir le tracé, était le plus souvent généré par le CPU ou processeur central généraliste. Il y avait bien les stations de travail pour les applications graphiques de Silicon Graphics, HP et Evans et Sutherland mais ça ne touchait pas le monde du PC que vous pouviez acheter au supermarché du coin. Dans ce monde, les « API graphiques » étaient un grand mot, on avait besoin d'instructions pour changer le mode graphique et pour allumer/éteindre un pixel à l'écran. Cela suffisait pour afficher des graphismes simples à la Castle Wolfenstein 3D qui en contrepartie avait besoin d'un CPU assez puissant (mais rien en comparaison de ce que l'on a maintenant). Pendant ce temps, les interfaces graphiques ont commencé à remplacer les vieilles interfaces textuelles et la multiplication des fenêtres et des applications graphiques gourmandes à la CorelDRAW/Photoshop ont créé un nouveau marché : celui des accélérateurs d'interface graphique (ou GUI accelerator), capables d'accéder directement à la mémoire sans faire appel au CPU (DMA ou direct memory access), de remplir des rectangles, polygones, tracer des lignes, voire de remplir des zones de l'écran avec des textures (en général une simple copie parfois avec redimensionnement). Ces capacités étaient les bienvenues dans le monde du PC qui devenait de plus en plus graphique mais il y avait un grand besoin de standardisation.
Quand quelqu'un écrit une application pour PC, s'il a une puce graphique spécialisée qui accélère certains calculs comme le tracé de polygones texturés, il pouvait avoir le choix d'utiliser les registres de la puce en question qui étaient documentés par le constructeur de la puce ou de faire appel à une interface de programmation standardisée pour laquelle le constructeur a fourni un logiciel pilote (aussi appelé driver en anglais). Ce logiciel pilote est donc le plus souvent chargé de faire le lien entre l'interface standardisée et les registres spécifiques du matériel. Notez que cette distinction n'est pas toujours aussi claire. Dans les premiers PC, le matériel était programmé avec les registres spécifiques. Et donc lorsque des clones de ces PC apparaissaient, ils se devaient d'émuler ces registres spécifiques même s'ils utilisaient une puce d'un constructeur différent. L'interface spécifique devenait donc le standard de facto. Il y a plusieurs niveaux de compatibilité : « pin compatible » ce qui permet de substituer physiquement les puces, ou de juste substituer les registres, juste les codes d'échappement ou juste créer une interception de plus haut niveau, comme les glide wrappers dans l'histoire plus récente. Cette situation peut arriver encore de temps à autre aujourd'hui mais à plus petite échelle.
Le monde du jeu vidéo cependant restait bloqué sur les interfaces bas niveau et s'il y avait de la standardisation (VESA), elle n'accélérait que le strict minimum (changement de mode d'affichage, accès en écriture direct à la mémoire d'affichage, double buffering). Ce qui fait que bien souvent, au début, les jeux vidéo continuaient à tourner sous l'interface textuelle de MS-DOS tandis que les applications « sérieuses » migraient sous Windows 3.1 avec l'accélération GDI. GDI était considérée comme trop lente pour ce que les développeurs de jeu voulaient faire et le fait de tourner sous Windows détournait une partie des ressources nécessaires aux jeux exigeants de l'époque.
La première tentative de faire migrer les développeurs de jeux sous Windows est venue avec WinG (prononcez « ouine-dji »). Là encore, la seule « accélération » proposée par WinG était en fait la suppression des couches intermédiaires qui empêchaient les développeurs de travailler directement sur la mémoire d'affichage. C'est-à-dire essayer de rendre une application Windows aussi rapide qu'elle pouvait l'être sous DOS. WinG est ensuite devenu DirectDraw, inclus dans DirectX 1 (aussi appelé GameSDK). Avec DirectX 1, Windows 95 était devenue une plate-forme de jeu à part entière sans raison de conserver MS-DOS comme une alternative viable.
Pendant ce temps-là, une autre révolution était en train d'arriver. Matrox, 3Dlabs, 3dfx, NVIDIA, PowerVR, Rendition lançaient quasi simultanément leurs accélérateurs 3D pour PC. Certains « accélérateurs » de cette époque étaient de simples évolutions des accélérateurs de GUI, ces derniers avaient la possibilité d'afficher des polygones texturés, les accélérateurs 3D étendaient cette capacité en ajoutant la possibilité de faire de l'interpolation perspective (interpolation avec coordonnée homogène W), parfois du filtrage (bilinéaire) et des opérations de blending (mélange de couleurs). Certains ne faisaient que ça, laissant le lourd héritage de la compatibilité aux acteurs établis. Chacune de ces entreprises avaient toutes en commun le but de devenir le seul acteur viable. Ce qui pourrait paraître comique aujourd'hui faisait sens à l'époque, chaque puce graphique avait sa propre interface de programmation. Les développeurs de jeu devaient donc choisir leur allégeance ou faire du code facilement adaptable. Ceux qui ont choisi la deuxième voie comme Criterion Games (RenderWare) ou RenderMorphics (Reality Lab) ont eu un destin un peu particulier, on y reviendra.
La situation s'est éclaircie rapidement, les développeurs de jeu ont plébiscité l'offre de 3dfx avec son interface propriétaire Glide. De plus en plus de jeux de l'époque ne proposaient que deux modes : le rendu logiciel (sur le CPU) ou matériel avec Glide.
Microsoft de son côté se retrouvait dans la même situation d'avant DirectDraw puisque tous les jeux migraient vers la 3D que DirectDraw n'accélérait pas. Plutôt que de développer sa propre interface 3D, certaines personnes poussaient Microsoft à adopter OpenGL. OpenGL tournait déjà sous Windows, il y avait une version qui tournait avec un rendu logiciel et des ports miniGL (pilote OpenGL minimal pour accélérateur graphique) qui faisaient tourner GLQuake par exemple. Mais Microsoft ne contrôlait pas OpenGL (initialement créé par Silicon Graphics, sa destinée était contrôlée par l'ARB, un consortium d'entreprises diverses et variées) : OpenGL ne bougeait pas assez vite (décision par comité), était un investissement lourd à supporter pour un constructeur spécialisé dans les pilotes bas niveau (les full OpenGL ICD n'arriveront pas avant quelques années et avec pas mal de « ratés »), et selon certains ne pouvaient pas supporter le degré d'accélération nécessaire pour les jeux de l'époque (rappelons que le rendu logiciel était encore important). Mais plutôt que de repartir de zéro, Microsoft avait racheté RenderMorphics, une entreprise qui développait des jeux et un moteur 3D. Reality Lab de RenderMorphics était un moteur fonctionnel avec graphe de scène haut niveau (ou scene graph) et une interface bas niveau qui permettait de faire tourner les jeux sur plusieurs types de matériels (une couche d'abstraction matérielle ou HAL). Peut-être que la focalisation en achetant RenderMorphics s'est trop portée vers l'accélération du rendu via le CPU, mais c'est sans doute plus facile à dire rétrospectivement que dans le feu de l'action de l'époque.

3dfx était encore trop occupé à promouvoir Glide, mais Microsoft pouvait compter sur le support fort d'Intel (avec i740), ATI (avec Rage 3D) et NVIDIA (avec Riva 128). Ces cartes avaient comme particularité de ne tourner qu'avec les API standards (Direct3D et OpenGL via miniGL au début puis Full OpenGL ICD par la suite), cela annonçait la fin des API propriétaires (pour la 3D). De plus, au même moment, la notion de carte exclusivement 2D disparaissait, il n'y avait plus que des cartes accélératrices 3D qui faisaient aussi de la 2D. Du même coup, tous les vendeurs qui ne faisaient que de la 2D ont été absorbés ou ont disparu.
Les révisions fréquentes de DirectX étaient nécessaires parce que les constructeurs annonçaient régulièrement le support de nouvelles fonctionnalités que l'ancienne version ne supportait pas. DirectX 3 était la première version à proposer Direct3D (Direct3D 1 = Direct3D 3 d'une certaine façon), basée entièrement sur Reality Lab avec le graphe de scène haut niveau et les execute buffers bas niveau. Direct3D 3 n'a pas plu à grand monde à l'exception de certains développeurs anglais. Microsoft a sauté DirectX 4 pour des problèmes de mauvais planning et a livré DirectX 5 avec une version améliorée de Direct3D. Les execute buffers étaient remplacés par des appels de fonctions explicites comme Clear(), DrawPrimitive(), SetRenderState() ce qui a fait taire les plus critiques de l'époque. Oui, cela semble incroyable aujourd'hui mais en pratique il s'agissait juste d'un rhabillage, les execute buffers étant toujours présents en coulisse mais cachés au programmeur.
Direct3D 6 apportait le multitexturing (possibilité de mixer deux textures en une seule passe, par exemple mélanger une lightmap avec une texture diffuse comme dans Quake 2). Direct3D 7 offrait pour la première fois le support de la transformation et de l'éclairage par les cartes graphiques (quelque chose qui était déjà possible sous OpenGL mais en pratique pas encore supporté par les cartes grand public), les textures cubes, les textures « managed », et un bond dans la complexité des textures stage states. Puis enfin est arrivée la programmabilité dans les textures stage states et dans la transformation et l'éclairage avec Direct3D 8 et ses pixel / vertex shaders.

Direct3D 9 a enfoncé le clou en étendant la programmabilité, en proposant le rendu vers des textures à précision flottante (16 bits et 32 bits flottants par canal) et en apportant une grande amélioration de l'interface de programmation elle-même. Chaque version de Direct3D était rétrocompatible avec la précédente. Cela veut dire plusieurs choses, 1 - il était possible de créer le même device identique sur toute carte graphique avec un support Direct3D 7 minimal. 2 - les applications écrites pour Direct3D 1-2-3-5-6-7-8 devaient pouvoir tourner sur les cartes graphiques qui avaient un pilote compatible Direct3D 9 (de même une application D3D 1 tournait sur 5, D3D 5 tournait sur 7, etc.). Cela a pas mal limité certains choix d'architecture de l'API elle-même et d'une certaine façon, les pilotes et le runtime ont pâti de cette nécessité de supporter plusieurs degrés de fonctionnalités avec la même interface. Mais c'était indispensable pour maintenir le taux de pénétration maximal de Direct3D dans le domaine du jeu - Direct3D étant entré en concurrence avec OpenGL dès ses débuts, concurrence qui ne s'est terminée qu'à la sortie de Direct3D 9.
Un an s'était écoulé entre D3D 3 (1996) et D3D 5 (1997), un an entre D3D 5 et D3D 6 (1998), encore un an entre 6 et 7 (1999), un peu plus d'un an entre 7 et 8 (2001) et un peu plus d'un an entre D3D 8 et D3D 9 (2002/2003). Comme on peut le voir, le rythme était très rapide. Mais ce n'était pas forcément un problème parce que les changements étaient très incrémentaux. Par ailleurs, au tout début de la 3D, le développement de jeu était rapide et parfois le code graphique était réécrit entre les jeux parce que les paradigmes changeaient rapidement (2.5D à 3D logiciel, 3D logiciel à « accéléré 3D », « accéléré 3D » à shaders).
Puis il y a eu un grand vide. Direct3D 9 était-elle la seule interface de programmation dont vous n'auriez jamais besoin ? Probablement pas, mais son successeur n'est pas sorti avant 2007 soit trois-quatre ans après son introduction ce qui aurait pu sembler une éternité dans le monde du développement de jeu et des cartes graphiques quelques années auparavant. Mais il y avait des signes qu'il n'y aurait pas besoin de plus pendant quelque temps. Le nombre de concurrents dans le secteur de la 3D grand public est dramatiquement tombé à trois (plus deux-trois qui ramassent les miettes). La rapidité d'innovation devenait plus difficile à maintenir avec des fonctionnalités de plus en plus complexes (la lecture de deux textures en simultané justifiait la sortie d'une nouvelle carte et d'une nouvelle API quelques années auparavant), des puces graphiques de plus en plus grosses (la validation elle-même prend des mois), des gammes qui s'étendent (3dfx avait un seul produit, la Voodoo1, remplacée plus tard par la Voodoo2 dans la même gamme de prix). Et puis un facteur important était que pour la première fois, Microsoft avait tenu à créer une API plus durable en faisant de Direct3D 9 la première version de Direct3D qu'aucun matériel ne pouvait accélérer complètement à sa sortie - les shaders 3.0 ont commencé à être supportés par les GeForce 6800 en avril 2004, les textures flottantes avec multisampling par la Radeon X1800 en octobre 2005.
Cela a des avantages et des inconvénients. Dans les inconvénients, d'un point de vue marketing, pendant trois ans, chaque mise à jour se distinguait de la version précédente grâce à un artifice marketing (comme Direct3D 9 « plus »). Et les trous dans l'API - malgré son excellent design de départ - sont devenus de plus en plus flagrants au cours des années.
Mais dans les avantages, il y a la stabilité que le non-changement d'API a apportée. Bien entendu, il y a des développeurs qui ont résisté et qui ont continué à distribuer des jeux programmés avec Direct3D 8 dans les deux ans qui ont suivi la sortie de Direct3D 9. En pratique, il est certain que cette stabilité a contribué à la force de Direct3D, notamment en accroissant son impact sur les développeurs aux dépens d'OpenGL. Encore aujourd'hui, dans des temps incertains, Direct3D 9 - qui ressemble de plus en plus à un bateau qui fuit de partout six ans après son introduction - reste l'API de référence pour les développeurs PC, sur plate-forme Windows bien entendu.

II. Direct3D 11▲
Deux à trois ans après l'introduction de Direct3D 10 (et une mise à jour mineure Direct 3D 10.1) Microsoft a annoncé la sortie imminente cette année de Direct3D 11.
Si on lit entre les lignes, avec Direct3D 11, on dirait que Microsoft plaide coupable pour certains choix qu'ils ont faits avec Direct3D 10. C'est paradoxal, parce qu'au premier abord Direct3D 11 sera fondamentalement proche de son prédécesseur tout en étant dramatiquement différent. Comment est-ce possible ?
II-A. Changement de cap▲
Direct3D 11 représente un changement de cap important de la part de Microsoft. Enfin au moins pour cette version-ci, on ne peut pas encore prédire si cette bonne volonté sera renouvelée avec la version suivante de l'API.
On se souvient que Direct3D 10 avait été présenté dès ses débuts comme lié à Windows Vista, choix qui a été vivement critiqué par les développeurs qui n'avaient pas la possibilité de développer prioritairement pour Vista. Loin d'être la killer app qui allait faire passer à Vista, cela a rallongé artificiellement la vie de Direct3D 9. On pouvait craindre que Direct3D 11 soit également lié à Windows Seven. Heureusement, Microsoft a entendu les développeurs et les clients cette fois-ci en faisant en sorte que Direct3D 11 tourne également sous Vista, mais pas sous XP. Verre à moitié vide ou à moitié plein, à vous de voir. Le fait est que si les développeurs démarrent le développement d'un nouveau moteur après le lancement de Direct3D 11, lorsque le moteur sera fini, il est possible que Vista et Seven aient une base installée suffisante pour pouvoir en faire une base exclusive.
Mais est-ce que ce sera suffisant pour que les développeurs choisissent la route Direct3D 11 uniquement ? Peut-être ou peut-être pas mais la décision sera aidée par ce qui suit.
L'un des autres reproches fait à Direct3D 10 était le fait que l'équipe DirectX avait préféré faire table rase du support matériel et redémarrer à zéro en supprimant les CAPS bits et les fonctionnalités inutilisées afin d'augmenter l'efficacité de l'API. Le résultat, bien entendu, c'est qu'à la sortie de Direct3D 10, une seule carte supportait l'API, c'était la GeForce 8. L'inertie du marché étant ce qu'elle est, un jeu vidéo pour être viable doit aussi tourner sur les cartes plus anciennes du marché : Radeon 9X/XX/X1, GeForce 5/6/7, Intel integrated, etc. Le fait est qu'un développeur de jeu avait beaucoup plus d'intérêt à développer un jeu exclusif Direct3D 9 qu'un jeu exclusif Direct3D 10 en 2009.
Gros changement : Direct3D 11 de son côté tournera sur toutes les cartes Direct3D 9 avec support WDDM (GeForce Fx/Radeon 9×00 dans les plus anciennes cartes supportées). Certes, c'est loin d'être parfait (le support WDDM exclut pas mal de vieilles cartes graphiques) mais c'est déjà beaucoup mine de rien. L'équipe DirectX a donc dû casser la belle interface Direct3D 10 pour y ajouter des « niveaux de compatibilité matérielle ». Ainsi, à la création du device Direct3D, il y a la possibilité de sélectionner les niveaux de compatibilité D3D_FEATURE_LEVEL_11_0, D3D_FEATURE_LEVEL_10_1, 10_0, 9_3, 9_2, 9_1.
Étant donné la parenté évidente de Direct3D 11 et Direct3D 10, supporter l'un avec l'autre n'est pas très surprenant. Mais Direct3D 9 et Direct3D 10 sont vraiment différents de prime abord. En pratique ce sera une concession à l'efficacité et l'exhaustivité (il ne sera pas possible de tout faire ce qui était possible sous Direct3D 9 avec ce nouveau type de device). Difficile de savoir comment sera le support en pratique et si cela sera largement adopté.
C'est une main tendue, d'une certaine façon, de Microsoft aux développeurs mais le but ultime c'est bien sûr d'accélérer l'acceptation de la nouvelle interface de programmation et l'acceptation des nouveaux OS par effet mécanique (lorsque tous les jeux seront exclusifs à ces OS, objectif a long terme).
III. Tessellation▲
Le mot tessellation vient du mot latin tessella qui a donné tesselle, c'est-à-dire le carreau dont est constitué une mosaïque. C'est une technique dite de « subdvision » où une surface est décrite de manière grossière et est raffinée petit à petit en rajoutant du détail géométrique.
La tessellation a de nombreux avantages. La forme non tessellée prend moins d'espace en mémoire et est moins lourde à manipuler : un artiste peut travailler sur une forme non tessellée et demander au logiciel de création de contenu (DCC) de rajouter des détails automatiquement avec une simple interpolation ou depuis une texture de détail (displacement mapping). De même, en temps réel, un jeu peut faire des calculs complexes sur la forme grossière avant d'envoyer le tout à la carte graphique. Les calculs complexes sont donc plus légers et l'affichage se fait sur un modèle agréable à l'œil sans trop d'arêtes vives. C'est la théorie.
Pour ceux qui suivent l'industrie graphique depuis quelque temps, la tessellation est un peu le serpent de mer de la 3D temps réel. Loin de moi l'idée d'être exhaustif mais voici un résumé. L'API graphique OpenGL proposait les evaluators. Ce sont des surfaces de Bézier (Bézier surface patch). Direct 3D 8 avait introduit de son côté deux types de surfaces « subdivisables » aussi appelées high order surfaces (par opposition aux triangles qui sont des surfaces d'ordre 1 dans la classification des surfaces polynomiales), les R/T patches et les N patches. Ce sont aussi des variations sur les surfaces et courbes de Bézier (la rapidité de l'évaluation des surfaces de Bézier est imbattable).
Si les cartes sorties avec Direct3D 8 les ont mis en avant, les cartes sorties après Direct3D 9 ont arrêté de les supporter. Le support des high order surfaces n'a donc été qu'une parenthèse dans l'histoire de Direct3D. La faute, sans doute, à un intérêt relatif réduit, à une faible flexibilité de l'implémentation, au manque du support du displacement mapping (qui a pourtant fait une rapide apparition sur la Matrox Parhelia mais qui n'a jamais été exposé sous Direct3D), à la difficulté à adapter le pipeline de production pour le support de la même géométrie avec et sans tessellation et probablement aussi le fait que la fonctionnalité X fonctionnait chez le vendeur de carte graphique X et la fonctionnalité Y fonctionnait chez le vendeur de carte graphique Y ce qui en limitait l'audience. Le reste c'est de l'histoire ancienne.
La tessellation a ensuite fait sa réapparition dans un contexte particulier : le Xenos (ou C1) de ATI devait supporter une forme de tessellation mais la puce était réservée à la Xbox 360 (ATI préférant sortir la plus traditionnelle Radeon X1800 sur le marché PC).
Dans les premiers documents parlant de DirectX Next (autre nom de Direct3D 10 dont le développement avait commencé après que Direct3D 9 avait été lancé), Microsoft avait présenté une de ses idées pour le nouveau pipeline graphique post Direct3D 9. Dans cette vision il y avait plusieurs vertex shaders (un pour chaque niveau de raffinement de la géométrie), une unité de tessellation (dont le fonctionnement n'a jamais été défini), un geometry shader et un pixel shader. Il est important de noter qu'initialement, le geometry shader n'avait pas pour but de faire de la subdivision de géométrie, cette tâche étant assignée à l'unité de tessellation. Au final on sait ce qu'il en est advenu. Des nouvelles unités imaginées au départ, seul le geometry shader a survécu, et le vertex shader est resté unique en amont du geometry shader. Le geometry shader n'était toujours pas conçu pour faire de la subdivision et les tentatives pour lui faire effectuer cette tâche ont échoué (les performances sont abyssales lorsque l'expansion des données géométriques est trop importante comme dans le cas d'une subdivision).
III-A. Détails d'implémentation▲
Le nouveau pipeline Direct3D 11 ressemble à ça :
input assembler (IA) -> vertex shader (VS) -> hull shader (HS) -> tessellator (TS) -> domain shader (DS) -> geometry shader (GS) -> rasterizer (RS) -> Pixel shader (PS) -> output merger (OM).
En gras sont les unités que Direct3D 11 a rajoutées. Il y a donc deux nouveaux types d'unité de shader (hull et domain) et une unité « fixe » appelée tessellator (tesselleur ? tessellateur ? À vos dicos !).
En gros, l'IA va lire les patches depuis le vertex buffer, chaque patch est décrit par le nombre de sommets qui constituent ce patch (de 1 à 32), ce qui permet de mixer plusieurs types de patches dans un seul draw call (ou récupérer des données générées par une passe précédente). Puis le vertex shader va faire des transformations sur ces sommets. S'il faut faire de l'animation lourde (blendshapes, simulation physique), c'est le moment de le faire. Le VS lit toujours un seul sommet en entrée et écrit un seul sommet en sortie. Le VS ne change pas de sémantique qu'il travaille sur des patches, des points, des triangles, etc. Les sommets ne sont - pas encore - des points de contrôle, du moins pas dans leur base définitive. On va voir par la suite comment interpréter ces sommets.
pd3dDeviceContext->
IASetPrimitiveTopology( D3D11_PRIMITIVE_TOPOLOGY_32_CONTROL_POINT_PATCHLIST );
pd3dDeviceContext->DrawIndexed(NumIndices, 0, 0 );On voit ci-dessus qu'il faut indiquer à l'IA (input assembler) que la topologie des sommets à transformer constitue un « patch » de 32 points (ou tout nombre inférieur). Les sommets qui constituent le patch sont passés en indice et envoyés à la carte via DrawIndexed(). Dans ce cas, il y a 32 sommets « potentiels » : ces sommets sont transformés puis sont passés en argument à la phase suivante.
Le HS est appelé une seule fois par patch. Mais l'une des particularités du HS est d'avoir des phases au nombre de deux. Ces phases ressemblent à des shaders indépendants dans le langage de description HLSL mais sont attachées toutes ensembles, de manière atomique, au hull shader. L'intérêt d'avoir des phases est la possibilité de séparer logiquement les parties indépendantes du hull shader et donc de donner l'opportunité au matériel d'exécuter ces phases en parallèle dans des unités de calcul séparées. Ces phases peuvent être invoquées plusieurs fois.
Quelles sont donc les phases en question ? La première est le calcul des constantes par patch (Hull shader path constant phase). C'est là que l'on va calculer le niveau de tessellation par exemple. Le niveau de tesselation (tesselation factor) est calculé pour chaque bord du patch. Calculer le facteur par bord de patch permet de faire en sorte que deux patches adjacents qui ont les mêmes sommets sur les bords aient également le même niveau de subdivision sur leur bord commun. C'est primordial pour éviter les trous et les superpositions, on parle dans ce cas de rasterisation étanche (watertight) lorsque tous les pixels d'une zone rasterisée sont couverts une fois et une seule fois. La deuxième phase est la phase des points de contrôle (Hull shader control point phase). Cette phase peut lire toutes les inputs du patch (les 32 sommets) et est exécutée une fois par point de contrôle déclaré.
[domain("quad")]
[partitioning("integer")]
[outputtopology("triangle_cw")]
[outputcontrolpoints(16)]
[patchconstantfunc("SubDToBezierConstantsHS")]
BEZIER_CONTROL_POINT SubDToBezierHS( InputPatch p,
uint i : SV_OutputControlPointID,
uint PatchID : SV_PrimitiveID )
{
}Par exemple dans le code ci-dessus, on a la déclaration du hull shader et la fonction appelée pendant la phase des points de contrôle. Les parties entre crochets représentent les paramètres que l'on passe à l'unité de tessellation fixe, à savoir que le domaine du patch est le quad (qui pourrait être un triangle ou une ligne), le partitionnement (division du domaine) se fait avec des nombres entiers, que la topologie sortante est composée des triangles dont les sommets sont donnés dans le sens des aiguilles d'une montre (clock wise), qu'il y a 16 points de contrôle à générer (la fonction SubDToBezierHS sera donc appelée 16 fois) et la fonction qui sera appelée pour la phase des constantes par patch est SubDToBezierConstantsHS(). Cette fonction-là sera appelée une seule fois par patch.
La fonction ci-dessus prend comme argument InputPatch<>. C'est un attribut généré par le système qui contient tous les sommets que l'on a déclarés qui appartiennent au patch en question (souvenez-vous : assemblés par l'IA et transformés par le VS). Il peut y avoir plus de sommets dans ce patch (MAX_POINTS) que de sommets déclarés en sortie (outputcontrolpoint(16)) tout simplement parce que l'on pourrait, par exemple, avoir envie de passer les sommets directement adjacents au patch pour améliorer la qualité de la future interpolation (watertight, continuité C0/C1, etc.).
Une fois le hull shader exécuté, le tessellator entre en action. Il va générer le « domaine » en question sans lire les points de contrôle. En fait son rôle est limité au minimum. Si le domaine est « patch », il va générer un carré paramétré par U,V entre 0 et 1, et le nombre de points générés sur ce carré va dépendre des tessfactors écrits par le HSPCH ci-dessus.
Pour chaque sommet généré par le tessellator, on va donc appeler la fonction déclarée pour le domain shader.
[domain("quad")]
DS_OUTPUT BezierEvalDS( HS_CONSTANT_DATA_OUTPUT input,
float2 UV : SV_DomainLocation,
const OutputPatch bezpatch )
{
}La fonction est précédée de la déclaration du domaine, ce qui est nécessaire pour associer le DS avec le HS correspondant (si ce n'était pas le cas, le DS risquerait de ne pas bien comprendre les arguments qu'on lui fournit). L'un des arguments de BezierEvalDS est le nombre U,V qui est celui généré par le tessellator par ce point. Cela ne veut pas dire que les coordonnées de texture sur ce point doivent obligatoirement varier entre 0 et 1, c'est juste une manière d'indiquer au DS où il se trouve sur le patch. Les coordonnées de texture, la couleur, les normales, les tangentes sont, elles, générées à l'intérieur de ce shader en prenant la partie constante HS_CONSTANT_DATA_OUTPUT qui arrive directement du HS sans passer par le tessellator et en la combinant avec le U,V généré. Par exemple, on peut imaginer que la coordonnée de texture Tex0 est une simple transformation affine des U,V par une matrice qui a été passée au préalable dans HS_CONSTANT_DATA_OUTPUT. Cette matrice a été calculée à partir des coordonnées Tex0 qui alimentaient le HS via ses points de contrôle. Voilà comment vous feriez en pratique (la matrice est ici décomposée en bilerp ou interpolation bilinéaire pour des raisons de simplicité) :
// bilerp the texture coordinates
float2 tex0 = input.vUV[0];
float2 tex1 = input.vUV[1];
float2 tex2 = input.vUV[2];
float2 tex3 = input.vUV[3];
float2 bottom = lerp( tex0, tex1, UV.x );
float2 top = lerp( tex3, tex2, UV.x );
float2 Tex0 = lerp( bottom, top, UV.y );Ce n'est pas la seule solution possible, il y a d'autres interpolations possibles par exemple pour les normales (l'interpolation bilinéaire n'a pas forcément la qualité désirée). Mais ne nous attardons pas là-dessus aujourd'hui.
Le résultat du domain shader est donc les sommets des triangles (ou des segments) qui composent notre patch de Bézier après son interpolation. Ces sommets sont ensuite envoyés au Geometry shader qui les traite comme s'ils venaient directement du vertex buffer. On a bien des triangles (ou segments) indépendamment de la nature du patch utilisé en amont (triangle ou quad ou ligne), tout simplement parce que c'est la seule primitive qu'accepte le rasterizer.
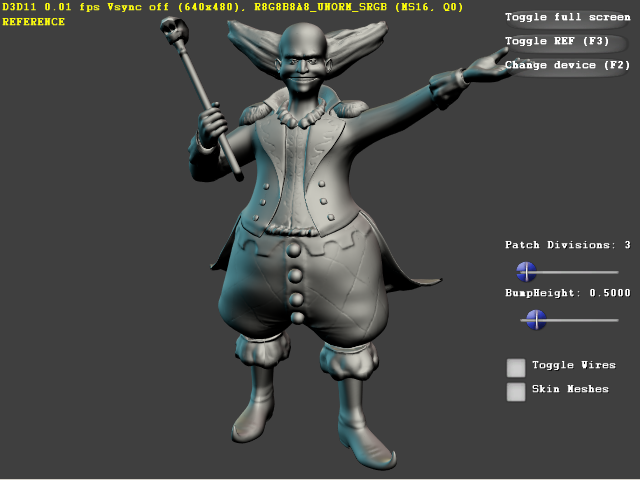
III-B. Limitations▲
Il y a plusieurs choses que l'on peut noter à partir des documentations qui ont été postées sur le web. On a parlé de surfaces de Bézier ci-dessus mais on peut voir que l'on n'est pas limité à ce type de représentation, la partie fixe se contente de générer une paramétrisation (u,v). Si on est capable d'évaluer une surface à partir d'une paramétrisation 2D alors il est possible d'évaluer cette surface avec notre unité de tessellation. Bézier est la sous-partie des surfaces paramétrées qui s'évaluent par des fonctions polynomiales des U,V.
Bien entendu, toutes les descriptions de surfaces ne se prêtent pas à la paramétrisation. Sans aller jusqu'aux fractales (un beau contre-exemple), des descriptions continues mais récursives comme les surfaces de subdivision avec points particuliers ne sont pas facilement paramétrables à proximité des points particuliers (c'est le « facilement » qui est important ici). Certaines courbes comme les courbes de Bézier sont trivialement paramétrables (même si on peut leur donner une définition par subdivision : cf. algorithme de Casteljau). L'exemple donné dans les présentations de Microsoft et de NVIDIA utilise une approximation de l'algorithme de Catmull-Clark par des patches bicubiques de Bézier. Et si l'on en croit les exemples donnés, l'aspect visuel est tout à fait satisfaisant. Donc, sauf si vous partez dans des ressources fractales, il est probablement faisable d'approcher vos surfaces avec des fonctions plus simples, voire de rester dans les fonctions bicubiques. La complexité de l'algorithme de subdivision lui-même est probablement secondaire si l'on peut générer des surfaces continues deux fois (au moins visuellement) et lire des détails depuis une texture.
La performance est en question. Quel niveau de tessellation peut-on attendre ? Est-ce que le simple fait d'activer l'unité de tessellation va faire chuter le frame rate avant même que l'on ait généré le premier sommet supplémentaire ? Question difficile à répondre de prime abord avant d'avoir vu le premier matériel tourner. Tout d'abord une évidence : il y a deux unités de shaders supplémentaires qui vont effectuer un travail non nul sur les unités de calcul (que se partageaient déjà le vertex/geometry/pixel shader). Donc il est évident qu'en cas de goulet d'étranglement sur ces unités de calcul, la performance globale risque de baisser. De plus, qui dit tessellation, dit génération d'un grand nombre potentiel de triangles supplémentaires, ces triangles seront plus petits (rendant la rasterisation moins efficace ?) et encombreront l'unité de setup/clipping, etc. augmentant la possibilité de goulet d'étranglement durant cette étape.
Bien entendu ce coût en performance sera contrebalancé par l'augmentation possible du visuel. Si les performances des nouvelles puces suivent, on aura une augmentation décente de la qualité d'image. On ne peut pas comparer des pommes et des oranges mais une augmentation comparable de la qualité d'image via un rendu « classique » sans tessellation aurait été coûteux en mémoire (stockage temporaire ou permanent des modèles), mais aussi du côté du CPU (envoi des données géométriques, voire tessellation partielle sur le CPU), et même coûteux lors de la transformation et de l'éclairage (vertex shader).
Un bon point cependant, même dans le cas où son coût le limite à des scénarios limités au début, il est probable que ce support ne disparaîtra pas dans le futur comme celui de la tessellation dans Direct3D 8. Tout simplement parce que la tessellation est devenue un composant obligatoire de Direct3D 11.
IV. Compute shaders▲
L'une des autres nouveautés de Direct3D 11 est le support des Compute Shaders (CS). Je n'ai pas représenté le compute shader dans le schéma du pipeline ci-dessus tout simplement parce que le CS ne s'intègre pas dans le pipeline graphique.
C'est une nouvelle unité fonctionnelle qui tourne indépendamment des notions de triangles, pixels, sommets. C'est la reconnaissance par Direct3D et Microsoft de l'importance du GPGPU ou programmation à but général sur GPU. Le GPGPU existe depuis quelque temps déjà. Au départ, l'idée d'exploiter les capacités de calcul parallèle des GPU s'est heurtée à la complexité de l'interface. En effet, afin de faire des opérations simples comme un « hello world ! » en GPGPU, il fallait apprendre une toute nouvelle interface de programmation qui le plus souvent introduisait des concepts totalement étrangers à ce que l'on voulait faire. Pourquoi des pixels, sommets, zbuffer quand on veut juste faire tourner une formule mathématique utilisée dans la finance ? Des cartes modernes (Tesla, Firestream) ne gèrent même plus l'affichage et ne s'encombrent pas du bagage de la programmation 3D dans leurs interfaces.
Bien entendu, c'est paradoxal que la reconnaissance du GPGPU passe par l'intégration dans une interface de programmation graphique. Mais c'est juste anecdotique. Le fait est que cela permet une standardisation, condition sine qua none pour que certains développeurs pensent à l'utiliser dans leurs jeux pour des calculs autres que le graphisme (physique, intelligence artificielle, etc.). Il est même possible d'imaginer via l'interaction entre Direct3D et Direct Compute que la partie Compute fasse une partie des calculs de rendu (si on se rend compte par exemple que la notion de sommet, pixel, zbuffer n'est plus indispensable pour certaines parties du rendu), on peut penser au raytracing, deferred shading,rendu par voxel, et j'en passe.
Il est possible que Direct Compute ne remplace pas totalement CUDA (ou autre) pour certaines applications « sérieuses » (Direct compute ne sera pas aussi multiplate-forme par exemple). Par ailleurs, pour l'instant le coût de passage d'un thread compute à un thread 3D n'est pas nul et pourrait nuire aux performances d'une application qui ferait du calcul pur par exemple.
Microsoft a fait la démonstration lors d'une réunion de développeurs de Direct Compute faisant tourner un kernel de post processing (Fast Fourier Transform). Ce module est fonctionnel en pré-alpha sur le matériel actuel (GeForce 8 de NVIDIA utilisé lors de la présentation). Les compute shaders seront, selon toute attente, accessibles sur certaines cartes existantes contrairement à la tessellation qui nécessitera une nouvelle architecture.
Un compute shader se programme de la même manière que tous les autres shaders avec un appel de fonction HLSL. Bien entendu, il y a quelques concessions, avec des instructions intrinsèques pour la synchronisation entre threads (XXXMemoryBarrier), les opérations atomiques sur les variables partagées (InterlockedXXX). Il est également possible de déclarer des ressources « RAW », c'est-à-dire libres de tout formatage particulier (pas de pixel format, de dimension, etc.) qui sont accédées depuis le compute shader par leur offset en nombre d'octets (byte offset). Il peut également accéder facilement aux ressources classiques rendues par les parties 3D (ce qui est tout de même l'un des fondements de cette intégration).
Comme le compute shader utilise les mêmes unités de calcul que la 3D, il n'y a pas d'exécution parallèle entre compute et 3D. Le compute shader et les opérations de tracé classiques doivent s'opérer les unes après les autres de manière sérialisée. Il faut par ailleurs limiter le nombre de va-et-vient entre les deux modes, puisque la transition n'est pas gratuite.

V. Multithreading▲
L'une des autres grosses nouveautés de Direct3D 11 est le rendu multithreadé.
L'idée, c'est qu'une partie non négligeable du temps par image dans un jeu est passé à générer des commandes pour faire tourner la carte graphique. C'est du coût « administratif » qui malheureusement ne peut pas être réduit davantage. Ou du moins pas aussi facilement que l'on voudrait.
Intel estimait récemment que 25 à 40 % du temps CPU par frame était passé dans le runtime et le pilote (pour un jeu moderne) et donc si l'on rajoute par-dessus les cycles additionnels que l'application doit dépenser pour conserver le GPU occupé à plein temps (traversal, système de matériau, gestion de la visibilité, systèmes de particules et généralement toute tâche attachée au graphisme), eh bien on peut probablement arriver à une majorité des cycles CPU passés pour gérer l'affichage. Je parle de coût administratif parce que même si le GPU fait le vrai boulot de rendu, le CPU doit lui soumettre des commandes de tracé en continu et en quantité importante pour les pixels « intéressants » (le coût CPU du pixel intéressant est toujours plus élevé que le coût CPU du pixel du benchmark synthétique).
L'arrivée du CPU multicore ne règle que partiellement le problème. Un exemple de réponse apportée, les pilotes récents vont créer des worker threads (thread « travailleur ») qui vont faire le vrai travail de programmation du matériel par opposition au thread d'acceptation des commandes. Cependant l'interface d'accès à l'API est toujours monothreadée (où doit être sérialisée au point d'avoir une performance monothread). Cette singularité rend difficile la parallélisation effective des tâches de rendu : il est toujours possible de faire le rendu en parallèle avec tout le reste mais si le rendu prend déjà tout le temps disponible et bien ça ne laisse qu'un faible répit. Si on ne fait rien suite à ça, on peut donc imaginer que la puissance des GPU continue d'augmenter exponentiellement, l'API ne progresserait pas en efficacité (coût administratif du pixel intéressant ne décroît pas), et la puissance d'un seul thread CPU ne progresserait pas, remplacée en pratique par une croissance en nombre de cores à la place. Au final on continuerait à sous-utiliser le potentiel de pixels intéressants du GPU.
Comment cela fonctionne ?
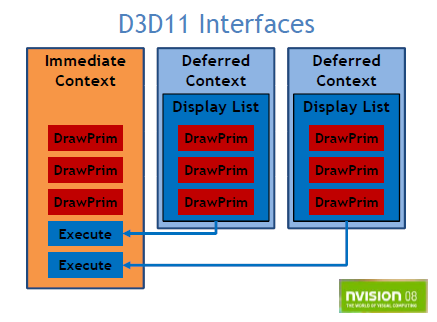
L'application va créer un device Direct3D 11 de manière normale puis va appeler la méthode CreateDeferredContext() sur ce device. Pour résumer, il y a deux types de contextes dans D3D 11. Le premier type est le contexte immédiat (immediate context). Il est retourné en sortie de D3D11CreateDevice() :
hr = DXUT_Dynamic_D3D11CreateDevice( pAdapter,
pNewDeviceSettings->d3d11.DriverType,
( HMODULE )0,
pNewDeviceSettings->d3d11.CreateFlags,
FeatureLevels,
NumFeatureLevels,
D3D11_SDK_VERSION,
&pd3d11Device,
&FeatureLevel,
&pd3dImmediateContext
);Le deuxième type est le contexte différé (deferred context). C'est ce type là qui est créé par CreateDeferredContext() :
pd3dDevice->CreateDeferredContext( 0 /*Reserved for future use*/,
&pd3dDeferredContext );L'envoi de commandes graphiques fonctionne de manière identique sur chaque contexte. La seule différence c'est que les commandes du contexte différé ne sont pas envoyées vers le pilote ni exécutées par le GPU directement.
Ces commandes sont mises à la place dans une liste de commandes (command list) qui est stockée de manière opaque (pour permettre plusieurs implémentations différentes, voir plus bas). Cette liste de commandes est récupérée lorsque l'on a fini le rendu sur le contexte différé :
pd3dDeferredContext->FinishCommandList( FALSE, &pd3dCommandList);Puis le pointeur récupéré de la liste de commandes est envoyé sur le contexte immédiat :
pd3dImmediateContext->ExecuteCommandList( pd3dCommandList, FALSE );Avertissement : chaque contexte a son propre jeu d'états, et donc le changement d'un render state dans un des contextes n'influe pas sur le render state d'un autre état et l'état des contextes est remis à zéro entre chaque exécution/finalisation de liste de commandes. Si vous faites :
deferredContext1->RSSetState(state 1)
deferredContext1->Draw()
deferredContext1->FinishCommandList(A)
deferredContext2->Draw()
deferredContext2->FinishCommandList(B)
immediateContext->RSSetState(state 2)
immediateContext->ExecuteCommandList(A) <- Ici Draw() est fait avec state 1
immediateContext->ExecuteCommandList(B) <- Ici Draw() est fait avec state par défaut
immediateContext->Draw() <- ici Draw() est fait avec l'état par défaut
deferredContext1->Draw()
deferredContext1->FinishCommandList(C)
immediateContext->ExecuteCommandList(C) <- state par défautLes commandes sont bien sérialisées quand elles sont soumises au GPU mais chaque contexte est considéré comme indépendant des autres. L'inconvénient c'est que, par contre, le passage d'un contexte différé à un autre va forcer le renvoi des états qui diffèrent, voire une réinitialisation complète, ce qui peut poser des problèmes de performance si l'opération de tracé qui a été différée n'est pas assez importante pour cacher ce coût. Les contextes différés doivent donc être conséquents pour qu'il n'y ait pas de perte de performance (avant même de parler de gain de performance).
Il y a tout de même des moyens d'hériter certaines propriétés, en effet même si les render states sont remis à zéro entre les exécutions/finalisations, ce n'est pas le cas des ressources Direct3D. Même si ne sont pas des render states à proprement parler, ils peuvent influencer l'exécution des opérations de tracé.
Comment peut-on donc gagner en performance avec ce mécanisme ?
Grâce à deux algorithmes. Le premier peut profiter à toute plate-forme, pas seulement celles qui sont fortement multithreadées. Il s'agit de constituer des listes de commandes qui seront tracées souvent mais ne changent pas souvent. Le coût de construction de la liste est donc factorisé, ne reste que le coût de l'exécution. Le deuxième bénéficie aux plates-formes fortement multithreadées, il s'agit de faire tourner des sous-parties de rendu de scène sur des threads différents. Avec un bon découpage il est possible d'occuper tous les cores avec des assemblages de scène et de réduire le thread principal à exécuter les listes de commandes.
Contrairement à la tessellation et aux compute shaders, c'est une fonctionnalité entièrement logicielle. C'est-à-dire qu'elle pourra fonctionner à la fois sur une nouvelle carte graphique Direct3D 11 et ses pilotes niveau 11_0, qu'une vieille carte Direct3D 9 et ses pilotes niveau 9_1.
Cependant chaque niveau de pilote va apporter un gain de performance différent. Le pilote de niveau 9 par exemple reste fortement sérialisé (avec éventuellement l'optimisation du worker thread qu'on a évoqué ci-dessus). La raison est que l'interface du pilote (DDI) a été pensée dans un univers monocore et que chambouler cette interface pour du matériel qui n'est plus en vente n'est pas très intéressant pour les vendeurs de cartes. Le support des contextes différés est donc émulé par le logiciel. Mais il peut tout de même y avoir un intérêt ne serait-ce que parce que l'application peut traiter sa partie de code comme des unités travaillant en parallèle ou minimiser le nombre d'appels à l'API. Le runtime aussi peut faire tourner une partie de ses calculs en parallèle et ne sérialiser qu'à la frontière du pilote.
Un nouveau type de pilote va faire son apparition pour apporter le maximum de gain à ces techniques, c'est le pilote free-threaded (fil d'exécution libre). La particularité de ce pilote c'est qu'il peut être appelé de n'importe quel thread en simultané (mais toujours sérialisé du point de vue du deferred context bien entendu) et qu'il ne doit pas bloquer l'exécution d'un thread du contexte 1 pour l'exécution d'un thread du contexte 2 (pour maximiser le parallélisme bien sûr). De plus, un pilote qui aurait le concept de contexte différé en vue pourrait assembler les listes de commandes dans un format natif, elles n'auraient alors plus qu'à être copiées en place finale lors de l'exécution. Ce pilote là bénéficiera grandement de la technique du préassemblage et exécution multiple, le coût total du préassemblage est factorisé sur les exécutions dont le coût CPU est réduit (théoriquement) à la copie. Bien entendu, c'est la théorie, reste à voir si les implémentations des différents constructeurs peuvent atteindre leur plein potentiel.
VI. Divers▲
Direct3D 11 offrira, en plus de toutes ces fonctionnalités, quelques mises à jour plus ou moins attendues.
Par exemple, le linker de shaders dynamique fera son apparition. Cela est censé résoudre le problème d'explosion combinatoire du système de matériel d'un jeu moderne. En effet, un matériel est souvent décrit par une flopée de bouts de codes qui peuvent être mis bout à bout de manière conditionnelle. Par exemple un objet diffus de base, peut devenir mouillé et récupérer un reflet spéculaire, puis peut être éclairé par un nombre de lumières variable, de différents types, avec des ombres précalculées ou dynamiques, avec du brouillard ou non, volumétrique ou global, et le tout modifié par un effet de vision XRay activable et désactivable à volonté par le joueur.
De nombreux éditeurs de jeux proposent par exemple aux artistes d'assembler des shaders avec des blocs de type Lego ce qui est sans doute pratique d'un point de vue artistique mais terriblement inefficace quand on pense à la somme de shaders différents générés qu'il faut ensuite envoyer à la carte graphique, convertir de HLSL en byte code du shader model 4, compiler pour le code natif de la carte, optimiser, etc. Une option envisageable était d'utiliser un über shader ou shader où tout le code possible est présent et simplement « activé ou non » par des constantes. Problème : c'est que le branchement n'est pas forcément gratuit, et que l'utilisation des ressources (textures, registres, inputs) doit s'accommoder du pire cas. De plus, le pilote pourrait très bien décider que l'über shader pourrait être mieux optimisé et recompilé au cas par cas. La solution du linker dynamique est donc une solution intermédiaire où les bouts de codes sont compilés indépendamment puis assemblés (en supposant que l'assemblage puisse être rapide) lors de l'exécution. Solution intermédiaire qui est sans doute meilleure que l'über shader ou la recompilation à tout-va, mais va-t-elle satisfaire les amateurs de performance ?

À cela il faut rajouter de nouvelles fonctionnalités mineures, comme le support de nouvelles textures compressées et optimisées pour les formats « HDR » (higher dynamic range). Des ajouts au support de Gather4 (lecture de quatre samples adjacents sous Direct3D 10.1 qui ne doivent plus forcément être adjacents dans Direct3D 11), des flux de sortie (stream output) adressables, la double précision, etc, etc, etc. Avec Direct3D 11, Microsoft a aussi annoncé un nouveau renderer logiciel appelé WARP Ten (en référence à Star Trek ?). Contrairement à Refrast (qui continue d'exister et qui reste la référence), Warp Ten peut être déployé en environnement de production et est optimisé pour la vitesse. L'objectif annoncé est d'offrir un fallback pour que plus d'applications utilisent Direct3D 10 pour leur rendu de base. Ce sera par exemple le cas du nouveau bureau de Windows Seven et du module Direct2D (un GDI/GDI+ accéléré).
VII. Conclusion▲
On a donc vu que Direct3D 11 est le fruit d'un long historique de développement des API graphiques par Microsoft. Et étrangement il reprend à son compte quelques choix de ses ancêtres que l'on croyait pourtant abandonnés (rétrocompatibilité, émulation logicielle).
Même si le rythme de sortie des API de Microsoft semble avoir largement ralenti, il y a encore des critiques qui l'estiment trop rapide. Pourtant les enjeux sont importants, les ajouts techniques sont indéniables et la nouvelle mouture s'offre même le luxe d'apporter de nouvelles fonctionnalités comme le device multithreadé et les compute shaders à des cartes existantes. Bref c'est une annonce excitante dans le monde de la 3D temps réel. On peut l'apprécier pour cela, tout en répétant qu'il ne faudra se précipiter dessus qu'après analyse préalable de vos besoins particuliers. Mais ce serait enfoncer des portes ouvertes.
VIII. À voir aussi▲
![]() Tesselation et subdivision de surfaces
Tesselation et subdivision de surfaces
![]() Présentation Compute Shaders par Chas Boyd
Présentation Compute Shaders par Chas Boyd