




I. Introduction▲
Vous n'allez pas découvrir des tours de magie fantastiques ici, la démo en elle-même ne présente pas le développement d'un code incroyable, mais j'ai toujours adoré lire les making-of d'autres démos, donc il est temps de prendre un peu de temps pour mettre ça à l'écrit.
Qu'est-ce qu'Ergon ? C'est une petite démo 4k (soit un exécutable de 4096 octets) qui a été publiée lors du 2010 Breakpoint demoparty (si vous ne pouvez pas la lancer sur votre machine, vous pouvez toujours la voir dans YouTube), qui de manière inattendue a pu finir à la troisième place. J'ai écrit le code, fait le design et aussi travaillé sur la musique avec mon ami Ulrick.
Cliquez pour lire la vidéo
C'était une expérience géniale même si je n'espérais pas travailler sur cette production au début de l'année… mais à la fin de janvier, quand BreakPoint 2010 était annoncée et supposée être la dernière, j'étais motivé pour y aller et, pourquoi pas, publier une démo 4k ! Un mois et demi plus tard, la démo était presque prête… wôw, trois semaines avant l’événement ! Mais oui, j'étais capable de travailler sur ce projet à mi-temps pendant la semaine (et la nuit bien sûr)… Mais quand j'ai commencé, je n'avais aucune idée où le projet m’amènerait… ou même de quelle API 3D je devais partir pour faire cette démo !
II. OpenGL, DirectX 9, 10 ou 11 ?▲
Chez Frequency, xt95 travaille principalement avec OpenGL, grandement dû au fait qu'il est un utilisateur Linux. Toutes nos démos précédentes ont été faites avec OpenGL, même si j'ai apporté un peu d'aide dans quelques démos et acheté un livre d'OpenGL il y a quelques années… Je ne suis pas un grand fan de la bibliothèque OpenGL, mais le plus important, d'après ma courte expérience sur le sujet, est que j'ai toujours été meilleur à réduire la taille d'un code DirectX que celle d'un code OpenGL… À cette époque, je travaillais aussi un peu plus avec l'API DirectX… J'ai même acheté plus tôt une 5770 ATI pour pouvoir jouer avec les compute shaders D3D11… Je suis aussi principalement un utilisateur Windows… DirectX a une documentation très bien intégrée à Visual Studio, un bon SDK, beaucoup d’exemples, une bibliothèque propre (vrai surtout pour D3D10/D3D11), quelques outils sympathiques comme PIX pour déboguer les shaders et je pensais aussi que programmer avec DirectX sous Windows pourrait réduire le risque d'avoir des incompatibilités entre les cartes graphiques NVIDIA et ATI (bien qu'en fait, avec au moins D3D9, ce n'est pas toujours vrai…).
Donc OK, DirectX était sélectionné… mais quelle version ? J'ai commencé ma première implémentation avec D3D10. Je sais que le code est plus parlant que D3D9 et OpenGL 2.0, mais je voulais aussi pratiquer un peu plus la nouvelle bibliothèque et non me contenter de simplement lire un livre sur son sujet. J'étais aussi intéressé pour ajouter du texte dans la démo et j'essayai une intégration avec la dernière bibliothèque Direct2D/DirectWrite.
Au début, tout allait bien avec l'API D3D10. Le code était propre, merci à la petite interface que j'ai développée autour de DirectX pour rendre le développement plus proche de ce que j'utilise d'habitude, comme du C# avec SlimDx. Le code C++ ressemblait à ça :
// Définit un VertexBuffer pour l'étape d'InputAssembler
device.InputAssembler.SetVertexBuffers(screen.vertexBuffer, sizeof(VertexDataOffline));
// Définit un TriangleList PrimitiveTopology pour l'étape d'InputAssembler
device.InputAssembler.SetPrimitiveTopology(PrimitiveTopology::TriangleStrip);
// Définit un VertexShader pour la passe
device.VertexShader.Set(effect.vertexShader);C'était très plaisant de développer avec, mais comme je voulais tester D2D1, je suis passé à D3D10.1 qui peut être configurée pour tourner sous du matériel supportant D3D10 (avec le même niveau de fonctionnalité)… Donc j'ai aussi commencé à légèrement encapsuler l'API Direct2D et j'étais capable de produire très facilement du joli texte… mais wôw… le code était un peu trop gros pour un 4k (mais serait parfait pour une 64k).
Alors pendant la phase d'expérimentation, j'ai essayé l'API D3D11 avec les compute shader… et ai trouvé que le code est bien plus compact qu'avec D3D10 si vous utilisez une quelconque sorte de… raymarching… Je n'ai pas comparé la taille du code, mais je le soupçonnais d'être en mesure de rivaliser avec son concurrent D3D9 (bien qu'il y ait un inconvénient avec D3D11 : si vous pouvez vous permettre d'avoir du vrai matériel D3D11, un compute shader peut directement effectuer le rendu sur le tampon de l'écran… autrement, avec l'utilisation des compute shaders D3D11 et ses fonctionnalités de niveau 10, il faut copier le résultat d'une ressource vers une autre… ce qui peut annuler le gain au niveau de la taille…).
J'étais content de voir que le passage à D3D11 était facile, avec une certaine continuité avec le « look & feel » de l'API D3D10… Bien que j'étais déçu d'apprendre que travailler sur D3D11 et D2D1 n'était pas direct parce que D2D1 est seulement compatible avec l'API D3D10.1 (que vous pouvez lancer avec les fonctionnalités de niveau 9.0 à 10), forçant à initialiser et maintenir deux périphériques (un pour D3D10.1 et un pour D3D11), jouant avec les ressources partagées DXGI entre les deux matériaux… wôw, beaucoup de travail, beaucoup de code… et bien sûr, hors de question pour une 4K….
Donc j'ai essayé… un vieux code pur D3D9… et c'était bien sûr plus compact en taille que leurs équivalents D3D10… Donc pendant environ deux semaines en février, j'ai joué avec ces différentes bibliothèques en implémentant quelques scènes basiques pour la démo. J'ai juste eu une mauvaise surprise en distribuant la démo, car beaucoup de personnes ne pouvaient pas la lancer : étrange, car je pouvais la lancer sur plusieurs cartes NVIDIA et au moins mon ATI 5770… je ne m'attendais pas à D3D9 d'être autant sensible à ça, ou du moins, d'être un peu moins sensible qu'OpenGL… mais j'avais tort.
III. Optimisation du Raymarching▲
J'ai décidé d'utiliser pour la démo l'algorithme de raymarching qui était capable de produire un contenu substantiel avec une faible quantité de code. Bien que le raymarching faisait déjà partie des « démodés » suite aux fantastiques démos sorties en début 2009 (Elevated – pas vraiment une démo raymarching, mais tellement impressionnante !, Sult, Rudebox, Muon-Baruon…). Mais je n'avais pas assez de temps pour explorer un nouvel effet et je n'étais même pas sûr de pouvoir trouver un truc intéressant à l'époque… alors… OK, pour le raymarching.
Donc pendant une semaine, après avoir fait une première scène, j'ai passé mon temps à essayer d'optimiser l'algorithme de raymarching. Il y avait un sujet instructif à propos de ça sur pouet : « Alors, à quoi ressemble leséquations du champ de distance, et comment les résoudre ? ». J'ai essayé d'implémenter quelques tours comme :
- Générer une grille à partir du vertex shader (avec une résolution de 4x4 pixels par exemple), pour précalculer une vue vierge de la scène, stocker la distance minimale à avancer avant de toucher la surface… laissant le pixel shader attendre les distances d'interpolation (multipliées par un petit facteur de réduction comme 0.9) et réaliser quelques affinements de raymarching avec moins d'itérations ;
- Générer un volume 3D prérendu de la scène avec une bien plus faible densité (comme 96x96x96) et utiliser cette carte pour naviguer dans le terrain tout en faisant des ajustements « sphere tracing » si besoin ;
- J'ai aussi essayé une sorte de niveau de détail sur la scène : par exemple, au lieu d'avoir une recherche de texture (pour le « bump mapping ») à chaque itération du raymarching, permettre au raymarcher d'utiliser une surface de scène simplifiée et passer à une version plus détaillée à la dernière étape.
Et bien, je dois admettre que toutes ces techniques n'étaient pas très intelligentes… et le résultat était en accord avec ce manque d'intelligence ! Aucune d'entre elles ne fournit une amélioration significative des performances en comparaison à l'augmentation de la taille du code généré.
Alors après une semaine d'optimisation, et bien, je suis simplement retourné à un algorithme basique de raymarcher. Le shader fut développé sous Visual C++, intégré dans le projet (merci à la coloration syntaxique de NShader). J'ai fait un petit outil en C# pour enlever les commentaires du shader, supprimer les espaces inutiles… intégrer dans la compilation (les événements de précompilation dans VC++). C'est vraiment agréable de travailler avec cet ensemble d'outils.
IV. Le design des scènes▲
Pour les scènes, j'ai décidé d'utiliser le même genre de technique utilisé dans la démo 4k Rudebox misant davantage sur la géométrie et les lumières, mais pas sur les matériaux. Cela a fait le succès de Rudebox et j'étais motivé pour faire quelques CSG avancés avec des opérations booléennes sur des éléments basiques (cube, sphère…). Le point positif avec cette approche est la possibilité d'éviter d'utiliser à l'intérieur de la surface ISO n'importe quelle sorte de si/alors/sinon pour déterminer le matériel… simplement laisser les lumières installées proprement dans la scène pour faire le travail. Oui, en effet, Rudebox est par exemple une scène avec disons, un matériel blanc pour tous les objets. Ce qui fait la différence est la position des lumières dans la scène, leur intensité… Ergon a utilisé la même astuce ici.
J'ai passé environ deux à trois semaines à développer les scènes. J'ai fini avec quatre scènes plutôt cool et un design consistant entre elles. Une des scènes utilisait des polices pour le rendu d'un mur de texte en raymarching.
Comme je ne suis pas sûr que je serai amené à utiliser ces scènes, et bien, je vais mettre leurs images d'écran ici !

La première scène que j'ai développée pendant mes expériences avec les API D3D9/D3D10/D3D11 était un modèle de tentacules massifs sortant d'un trou noir. Tous les tentacules bougeaient autour d'une sphère bizarre et découpée, avec un œil central… j'étais assez heureux avec cette scène qui avait un design unique. Depuis le début, je voulais ajouter quelques posttraitements pour améliorer le visuel et pour me démarquer un peu des autres scènes de raymarching… Donc j'y suis allé avec un posttraitement simple qui réalisait quelques motifs sur les pixels, ajoutant un flou radial pour produire une sorte de « rayon fantôme » sortant de la scène, rendant les coins plus sombres et ajoutant un petit scintillement à mesure que vous vous rapprochiez des coins. Et bien, seul ce morceau de code prenait déjà la scène pour lui seul, mais c'était le prix à payer pour avoir une véritable ambiance, donc…
Les couleurs et le thème étaient presque réglés depuis le début… je suis un grand fan des couleurs chaudes !
La deuxième scène utilisait une police de rendu ajoutée au raymarcher… une sorte de drapeau volant, avec le logo FRequency apparaissant dessus de gauche à droite… (Pour information, je vais probablement publier ces effets sur pouet.) C'était aussi une utilisation nouvelle de la technique de raymarching… Je n'avais rien vu de similaire dans les dernières démos 4k, donc, j'espérais insérer ce texte dans la démo, et ce n'est pas si évident… Le code qu'utilise la police d3d n'était pas trop gros… donc j'étais toujours confiant d'être en mesure d'utiliser ces deux scènes.
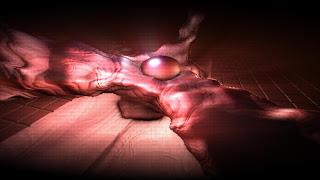
Après ça, je cherchais des objets sales… donc pour la troisième scène, j'ai essayé de manière aléatoire de jouer avec quelques fonctions bizarres et j'ai terminé avec une sorte de créature « raptor »… Je voulais utiliser une texture générée bizarre que j'avais trouvée il y a quelques mois, c'était parfait pour ça.
Finalement, je voulais utiliser la texture pour faire une sorte de mer de lave avec un serpent se déplaçant à l'intérieur… c'était la dernière scène que j'ai écrite (et bien sûr, deux scènes sont trop moches pour être montrées ici !:) ).

À cette époque, en février, nous avons aussi commencé à travailler sur la musique, et comme je l'ai expliqué dans mes posts plus récents, nous utilisions 4klang synth pour la démo. Mais en faisant toutes ces scènes avec un prototype de musique, l’exécutable compressé était plutôt autour de 5 ko… même si le code des shaders était déjà optimisé en taille, utilisant quelques sortes de modèles préprocesseurs (comme le « rudebox » ou le « récepteur »). La démo manquait bien sûr d'une direction claire, il n'y avait pas de transitions entre les scènes… et encore plus important, il n'était pas possible d'intégrer toutes les scènes dans la démo, alors qu'on espérait augmenter un peu la taille de la musique dans l'exécutable final…
V. L'histoire de la texture des vers de lave▲
L'année dernière, autour du mois de novembre, pendant que je jouais avec différents bruits de Perlin, j'ai trouvé une variation intéressante en utilisant un bruit de Perlin et l'effet marble-cosin qui était en mesure de représenter quelques sortes de vers, plutôt moches et effrayants. Mais c'était un effet de texture unique.

La texture était principalement développée en C#, mais le code était assez simple à porter en texture shader… Oui, c'était probablement une ancienne astuce avec D3D9 d'utiliser la fonction D3DXFillTextureTXto pour directement remplir une texture depuis un shader avec une seule ligne de code… Pourquoi utiliser ça ? Parce que c'était le seul moyen d'obtenir une fonction bruit() accessible depuis un shader, sans avoir à l'implémenter… Aussi étrange que cela puisse paraitre, la fonction HLSL perlin noise() n'est pas accessible en dehors d'un texture shader. Un énorme inconvénient de cette méthode est aussi que le shader n'est pas un vrai shader sur GPU, mais est calculé avec le CPU… ce qui explique pourquoi la démo ergon prend tant de temps pour générer la texture au début (avec une texture de résolution 1280 x 720 par exemple).
Alors à quoi ressemble ce texture shader permettant de générer cette texture ?
// -------------------------------------------------------------------------
// worm noise function
// -------------------------------------------------------------------------
#define ty(x,y) (pow(.5+sin((x)*y*6.2831)/2,2)-.5)
#define t2(x,y) ty(y+2*ty(x+2*noise(float3(cos((x)/3)+x,y,(x)*.1)),.3),.7)
#define tx(x,y,a,d) ((t2(x, y) * (a - x) * (d - y) + t2(x - a, y) * x * (d - y) + t2(x, y - d) * (a - x) * y + t2(x - a, y - d) * x * y) / (a * d))
float4 x( float2 x : position, float2 y : psize) : color {
float a=0,d=64;
// Modified FBM functions to generate a blob texture
for(;d>=2;d/=2)
a += abs(tx(x.x*d,x.y*d,d,d)/d);
return a*2;
}La macro ty applique principalement un pavage sur le bruit.
Les macros t2 et ty sont celles capables de générer ce « bruit de ver ». C'est en fait une combinaison astucieuse de l'habituel bruit de Perlin cosinus. Au lieu d'avoir quelque chose comme cos(x + bruit(x,y)), j'ai quelque chose comme spéciale_sin(y + spéciale_sin(y + bruit(cos(x/3) + x, y), puissance1), puissance3), avec la fonction spéciale_sin comme ((1 + sin(x*puissance*2*PI))/2) ^ 2.
Aussi, ne soyez pas effrayé… cette formule ne m'est pas sortie de la tête comme ça… c'était clairement après beaucoup de permutations de la fonction originale, avec beaucoup d'étapes de « lancer/arrêter/changer les paramètres ». :D
VI. Musique et synchronisation▲
Cela m'a pris un peu de temps pour faire le thème de la musique et en être satisfait… Au début, je laissais Ulrick faire la première version de la musique… Mais parce que j'avais une vue claire du design et de sa direction, j'espérais une progression très spécifique dans le ton et même dans les cordes utilisées… C'était vraiment ennuyeux pour Ulrick (excuse-moi mon ami !), surtout que j'étais très intrusif dans le processus de la composition… À un moment donné, j'ai fini par faire deux modèles d'exemple de ce que je voulais en termes de cordes et d'ambiance de musique… et Ulrick était assez gentil pour prendre ces échantillons et malin pour ajouter dedans quelques sentiments de musique de démo. Il sera mieux placé que moi pour parler de ça, donc je lui demanderai s'il peut insérer une explication ici !
Ulrick : « Travailler avec @lx sur cette production était un travail très agréable. J'ai commencé une musique que @lx n'aimait pas beaucoup, elle ne reflétait pas les sentiments que @lx voulait donner à travers Ergon. Il a alors composé quelques modèles en utilisant une gamme musicale très émotionnelle. Je suis entré dans la musique très facilement et j'ai ajouté mes propres trucs. Pour l'anecdote, j'ai ajouté une deuxième gamme pour permettre une transition plus claire entre la première et la deuxième partie d'Ergon. Après avoir fait ça, nous nous sommes rendu compte que notre musique utilisait en fait une gamme chromatique en mi. »
La synchronisation était la dernière partie du travail de la démo, j'ai tout d'abord utilisé les mécanismes de synchronisation par défaut de 4klang… mais je manquais de fonctionnalités : si la démo tournait doucement, je devais savoir exactement où j'étais… Utilisant complètement la synchronisation 4klang, je manquais quelques événements sur les matériels lents, pouvant même empêcher la démo de passer d'une scène à l'autre parce que l’événement de changement de scène était sauté par la boucle de rendu !
Donc j'ai fait ma propre petite synchronisation basée sur des événements réguliers de la caisse claire et une vue réduite des modèles d'exemple pour ces événements particuliers. Cette partie était la seule de la démo qui était développée en assembleur x86 pour la garder le plus petit possible.
L'ensemble du code ressemblait à ça :
static float const_time = 0.001f;
static int SAMPLES_PER_DRUMS = SAMPLES_PER_TICK*16;
static int SAMPLES_PER_DROP_DRUMS = SAMPLES_PER_TICK*4;
static int SMOOTHSTEP_FACTOR = 3;
static unsigned char drum_flags[96] = {
// pattern n° time z.z sequence
1,1,1,1, // pattern 0 0 0 0
1,1,1,1, // pattern 1 7,384615385 4 1
0,0,0,0, // pattern 2 14,76923077 8 2
0,0,0,0, // pattern 3 22,15384615 12 3
0,0,0,0, // pattern 4 29,53846154 16 4
0,0,0,0, // pattern 5 36,92307692 20 5
0,0,0,0, // pattern 6 44,30769231 24 6
0,0,0,0, // pattern 7 51,69230769 28 7
0,0,0,1, // pattern 8 59,07692308 32 8
0,0,0,1, // pattern 8 66,46153846 36 9
1,1,1,1, // pattern 9 73,84615385 40 10
1,1,1,1, // pattern 9 81,23076923 44 11
1,1,1,1, // pattern 10 88,61538462 48 12
0,0,0,0, // pattern 11 96 52 13
0,0,0,0, // pattern 2 103,3846154 56 14
0,0,0,0, // pattern 3 110,7692308 60 15
0,0,0,0, // pattern 4 118,1538462 64 16
0,0,0,0, // pattern 5 125,5384615 68 17
0,0,0,0, // pattern 6 132,9230769 72 18
0,0,0,0, // pattern 7 140,3076923 76 19
0,0,0,1, // pattern 8 147,6923077 80 20
1,1,1,1, // pattern 12 155,0769231 84 21
1,1,1,1, // pattern 13 162,4615385 88 22
};
// Calcule le temps, le pas de synchronisation et les variables du shaders de l'explosion
__asm {
fild dword ptr [time] // st0 : time
fmul dword ptr [const_time] // st0 = st0 * 0.001f
fstp dword ptr [shaderVar.x] // shaderVar.x = time * 0.001f
mov eax, dword ptr [MMTime.u.sample]
cdq
sub eax, SAMPLES_PER_TICK*8
jae not_first_drum
xor eax,eax
not_first_drum:
idiv dword ptr [SAMPLES_PER_DRUMS] // eax = drumStep , edx = remainder step
mov dword ptr [drum_step], eax
fild dword ptr [drum_step]
fstp dword ptr [shaderVar.z] // shaderVar.z = drumStep
not_end: cmp byte ptr [eax + drum_flags],0
jne no_boom
mov eax, SAMPLES_PER_TICK*4
sub eax,edx
jae boom_ok
xor eax,eax
boom_ok:
mov dword ptr [shaderVar.y],eax
fild dword ptr [shaderVar.y]
fidiv dword ptr [SAMPLES_PER_DROP_DRUMS] // st0 : boom
fild dword ptr [SMOOTHSTEP_FACTOR] // st0: 3, st1-4 = boom
fsub st(0),st(1) // st0 : 3 - boom , st1-3 = boom
fsub st(0),st(1) // st0 : 3 - boom*2, st1-2 = boom
fmul st(0),st(1) // st0 : boom * (3-boom*2), st1 = boom
fmulp st(1),st(0)
fstp dword ptr [shaderVar.y]
no_boom:
};C'était plus petit que ce que je pouvais faire avec de la pure synchronisation 4klang… avec le désavantage que la synchronisation était probablement trop simpliste… mais je ne pouvais pas me permettre plus de code pour la synchronisation… donc…
VII. Mixage final▲
Une fois la musique presque terminée, j'ai passé quelques jours à travailler sur les transitions, la synchronisation et les mouvements de la caméra. Comme ce n'était pas possible de placer les quatre scènes, j'ai dû mixer la troisième scène (le raptor) avec la quatrième (le serpent et la mer de lave), trouvant un moyen de mettre une transition à travers un « cerveau central ». Ulrick voulait mettre un style de musique différent pour la transition, je n'étais pas confiant… jusqu'à ce que je mette la transition en action, laissant le cerveau s'effondrer dans l'espace sous lequel il creusait tout autour… et la musique allait vraiment bien avec ! Cool !
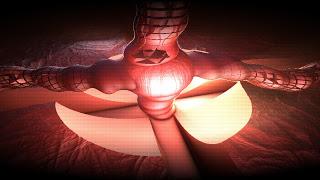
J'ai aussi utilisé un simple gros shader pour l'ensemble de la démo, avec quelques si (time < x) alors scène_1 sinon scène_2… Je ne voulais pas faire ça, parce que cela heurtait les performances du pixel shader de faire ce genre de traitement… Mais je manquais vraiment d'espace et la seule solution était en fait d'utiliser un unique shader avec quelques bouts de code répétitifs. Voici un extrait du code du shader : vous pouvez voir comment la scène et la gestion de la caméra ont été faites, de même pour l'éclairage. Cette partie se compressait assez bien, dû à son modèle répétitif.
// -------------------------------------------------------------------------
// t3
// Fonction d'aide pour tourner un vecteur. Usage :
// t3(mypoint.xz, .7); <= tourne mypoint autour de l'axe Y avec 0.7 radians
// -------------------------------------------------------------------------
float2 t3(inout float2 x,float y){
return x=x*cos(y)+sin(y)*float2(-x.y,x.x);
}
// -------------------------------------------------------------------------
// v : fonction principale de raymarching
// -------------------------------------------------------------------------
float4 v(float2 x:texcoord):color{
float a=1,b=0,c=0,d=0,e=0,f=0,i;
float3 n,o,p,q,r,s,t=0,y;
int w;
r=normalize(float3(x.x*1.25,-x.y,1)); // ray
x = float2(.001,0); // epsilon factor
// Gestion de scène
if (z.z<39) {
w = (z.z<10)?0:(z.z>26)?3+int(fmod(z.z,5)):int(fmod(z.z,3));
//w=4;
if (w==0) { p=float3(12,5+30*smoothstep(16,0,z.x),0);t3(r.yz,1.1*smoothstep(16,0,z.x));t3(r.xz,1.54); }
if (w==1) { p=float3(-13,4,-8);t3(r.yz,.2);t3(r.xz,-.5);t3(r.xy,sin(z.x/3)/3); }
if (w==2) { p=float3(0,8.5,-5);t3(r.yz,.2);t3(r.xy,sin(z.x/3)/5); }
if (w==3) {
p=float3(13+sin(z.x/5)*3,10+3*sin(z.x/2),0);
t3(r.yz, sin(z.x/5)*.6);
t3(r.xz, 1.54+z.x/5);
t3(r.xy, cos(z.x/10)/3);
t3(p.xz,z.x/5);
}
if (w == 4) {
p=float3(30+sin(z.x/5)*3,8,0);
t3(r.yz, sin(z.x/5)/5);
t3(r.xz, 1.54+z.x/3);
t3(r.xy, sin(z.x/10)/3);
t3(p.xz,z.x/3);
}
if (w > 4) {
p=float3(4.5,25+10*sin(z.x/3),0);
t3(r.yz, 1.54*sin(z.x/5));
t3(r.xz, .7+z.x/2);
t3(r.xy, sin(z.x/10)/3);
t3(p.xz,z.x/2);
}
} else if (z.z<52) {
p=float3(20,20,0);
t3(r.yz, .9);
t3(r.xz, 1.54+z.x/4);
t3(p.xz,z.x/4);
} else if (z.z<81) {
w = int(fmod(z.z,3));
if (w==0 ) {
p=float3(40+sin(z.x/5)*3,8,0);
t3(r.yz, sin(z.x/5)/5);
t3(r.xz, 1.54+z.x/3);
t3(r.xy, sin(z.x/10)/3);
t3(p.xz,z.x/3);
}
if (w==1 ) {
p=float3(-10,30,0);
t3(r.yz, 1.1);
t3(r.xz, z.x/4);
}
if (w==2 ) {
p=float3(25+sin(z.x/5)*3,10+3*sin(z.x/2),0);
t3(r.yz, sin(z.x/5)/2);
t3(r.xz, 1.54+z.x/5);
t3(r.xy, cos(z.x/10)/3);
t3(p.xz,z.x/5);
}
} else {
p=float3(0,4,8);
t3(r.yz,sin(z.x/5)/5);
t3(r.xy,cos(z.x/4)/2);
t3(r.xz,-1.54+smoothstep(0,4,z.x-155)*(z.x-155)/3);
}
// Effets d'explosion sur la caméra
p.x+=z.y*sin(111*z.x)/4;
// Lumières
static float4 l[6] = {{.7,.2,0,2},{.7,0,0,3},{.02,.05,.2,7},
{(4+10*step(24,z.z))*cos(z.x/5),-5,(4+10*step(24,z.z))*sin(z.x/5),0},
{-30+5*sin(z.x/2),8,6+10*sin(z.x/2),0},
{25,25,10,0}
};VIII. Statistiques de la compression▲
Les résultats finals de la compression sont donnés dans la table suivante :
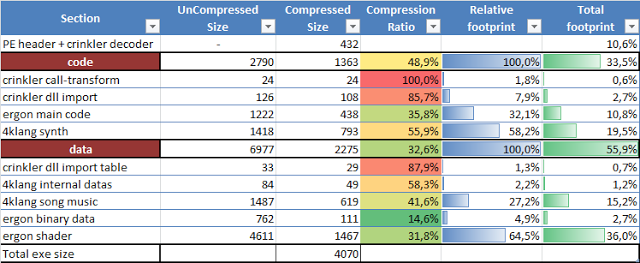
Donc pour résumer, la taille totale de l'exécutable est de 4070 octets, et est composée de :
- code de la synchronisation + données musicales prennent autour de 35 % de la taille totale de l'exécutable = 1461 octets ;
- code des shaders prend 36 % = 1467 octets ;
- code principal + données non shader prennent 14 % = 549 octets ;
- PE + décodeur crinkler + importateur crinkler prennent 15 % = 593 octets.
La démo était terminée autour de mars 2010, bien avant la BP2010. Donc j'étais bien cool… J'ai passé le reste de mon temps jusqu'à BP2010 à essayer de développer un gfx 4k procédural, utilisant les shaders calculés avec D3D11, du raymarching et des algorithmes d'illumination globale… mais les résultats (algo terminé pendant l'événement) m'ont déçu… Et quand j'ai vu le fantastique Burj Babil par Psycho, il avait raison d'utiliser un raymarcher complet sans aucun système de gestion de lumière compliqué… un bon algorithme « basique» de raymarching avec quelques transformations de tons finement réglées était plus pertinent ici !
Peu importe, mon expérience avec le compute shader méritera probablement un article ici.
J'ai vraiment adoré faire cette démo et voir que Ergon était capable de finir dans le top 3… après avoir vu BP2009, je n'espérais pas du tout que ma démo finisse dans le top 3 …! Bien que je savais que la compétition cette année était bien plus facile que la BP précédente !
En tout cas, c'était agréable de travailler avec mon ami Ulrick… et de contribuer à la scène de démo avec sa production. J'espère que je serai capable de continuer de travailler sur des démos comme ça… J'ai encore beaucoup de choses à apprendre, et ça, c'est cool !
IX. Remerciements▲
Merci à Alexandre Mutel de nous avoir permis de traduire son article.
Merci à Voïvode pour sa correction orthographique.